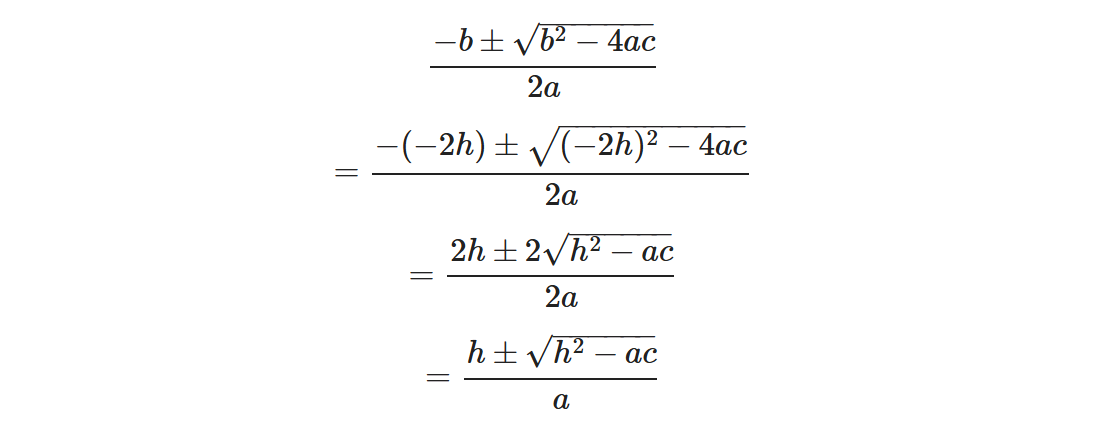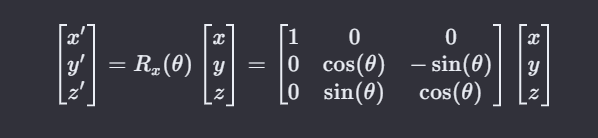classsphere: public hittable{ public: sphere(const point3& center, double radius) : center(center), radius(std::fmax(0,radius)) { }
boolhit(const ray& r,interval ray_t,hit_record& rec)constoverride{ vec3 oc = center - r.origin(); auto a = r.direction().length_squared(); auto h = dot(r.direction(),oc); auto c = oc.length_squared() - radius*radius;
voidwrite_color(std::ostream& out,const color& pixel_color){ auto r = pixel_color.x(); auto g = pixel_color.y(); auto b = pixel_color.z();
//从线性空间到伽马空间的转换 r = linear_to_gamma(r); g = linear_to_gamma(g); b = linear_to_gamma(b);
//使用区间RGB[0,1]计算RGB值 staticconst interval intensity(0.000,0.999); int rbyte = int (256*intensity.clamp(r)); int gbyte = int (256*intensity.clamp(g)); int bbyte = int (256*intensity.clamp(b));
voidwrite_color(std::ostream& out,const color& pixel_color){ auto r = pixel_color.x(); auto g = pixel_color.y(); auto b = pixel_color.z(); //使用区间RGB[0,1]计算RGB值 staticconst interval intensity(0.000,0.999); int rbyte = int (256*intensity.clamp(r)); int gbyte = int (256*intensity.clamp(g)); int bbyte = int (256*intensity.clamp(b)); out << rbyte << ' ' << gbyte << ' ' << bbyte << '\n'; }
doublehit_sphere(const point3& center,double radius,const ray& r){ vec3 oc = center - r.origin(); auto a = dot(r.direction(),r.direction()); auto b = -2.0 * dot(r.direction(),oc); auto c = dot(oc,oc) - radius*radius; auto discriminant = b*b - 4*a*c; //判断delta值,并计算t(这里计算的是较小的t) if(discriminant < 0.0){ return-1.0; }else{ return (-b - std::sqrt(discriminant)) / (2.0*a); } }
color ray_color(ray & r){ auto t = hit_sphere(point3(0,0,-1),0.5,r); //根据t的分量进行上色 if(t > 0.0){ vec3 N = unit_vector(r.at(t) - point3(0,0,-1)); return0.5*color(N.x()+1,N.y()+1,N.z()+1); }
vec3 unit_direction = unit_vector(r.direction()); auto a = 0.5*(unit_direction.y() + 1.0); return (1.0-a)*color(1.0,1.0,1.0) + a*color(0.5,0.7,1.0); }
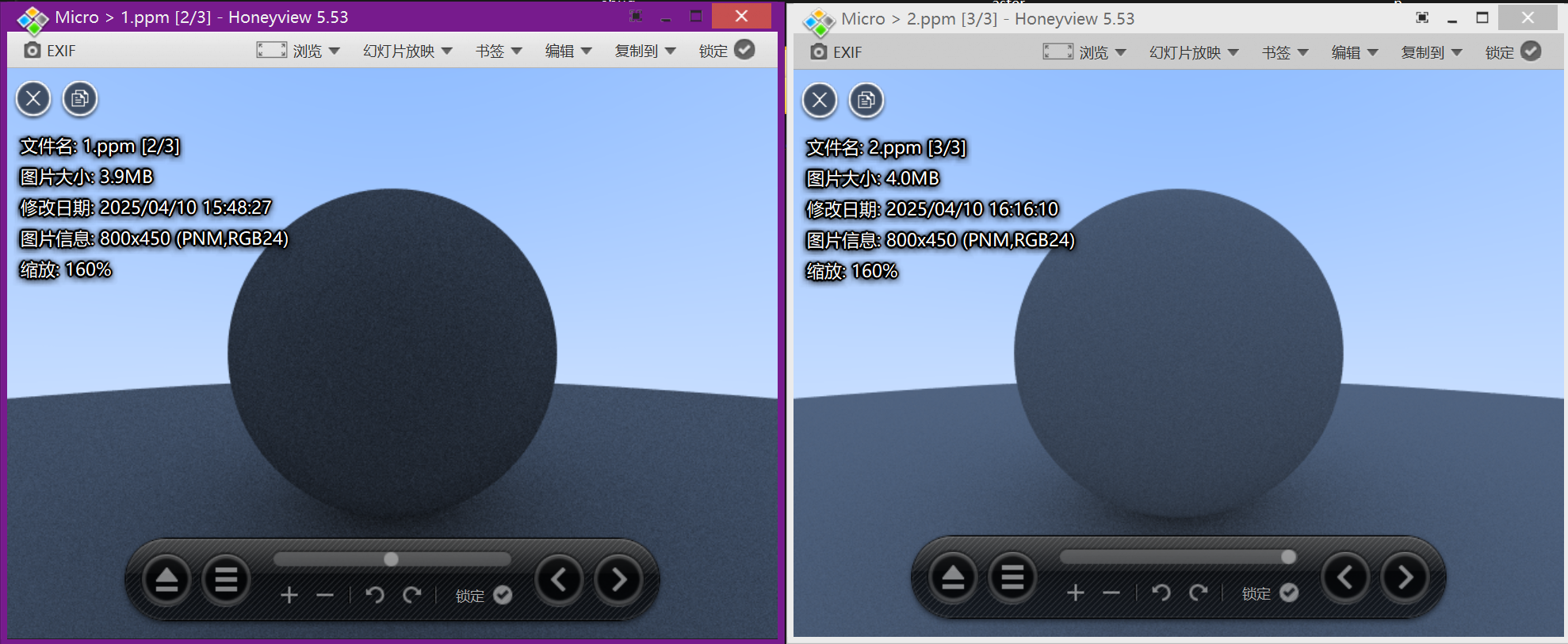
我们将程序修改后运行渲染得到了新的图片:
image.png
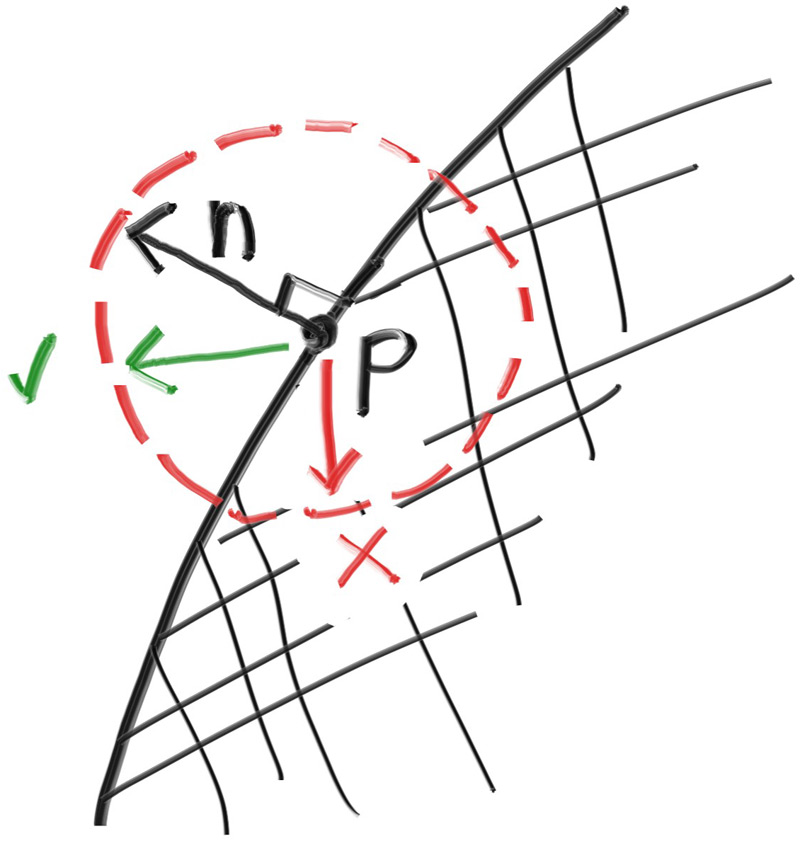
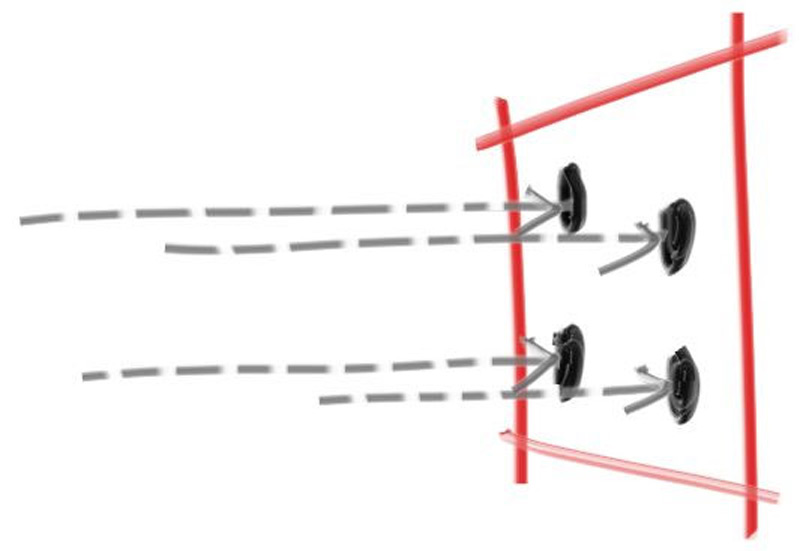
光线计算的简化
我们查看原本的交点计算方程:
1 2 3 4 5 6 7 8 9 10 11 12 13
doublehit_sphere(const point3& center,double radius,const ray& r){ vec3 oc = center - r.origin(); auto a = dot(r.direction(),r.direction()); auto b = -2.0 * dot(r.direction(),oc); auto c = dot(oc,oc) - radius*radius; auto discriminant = b*b - 4*a*c;
doublehit_sphere(const point3& center,double radius,const ray& r){ vec3 oc = center - r.origin(); auto a = r.direction().length_squared(); auto h = dot(r.direction(),oc); auto c = oc.length_squared() - radius*radius; auto discriminant = h*h - a*c;
classsphere: public hittable{ public: sphere(const point3& center, double radius) : center(center), radius(std::fmax(0,radius)) {} //fmax返回两个浮点数参数较大的一个,fmin同理 boolhit(const ray& r, double ray_min,double ray_max,hit_record& rec)constoverride{ vec3 oc = center - r.origin(); // override 重写基类的虚函数 auto a = r.direction().length_squared(); auto h = dot(r.direction(),oc); auto c = oc.length_squared() - radius*radius;
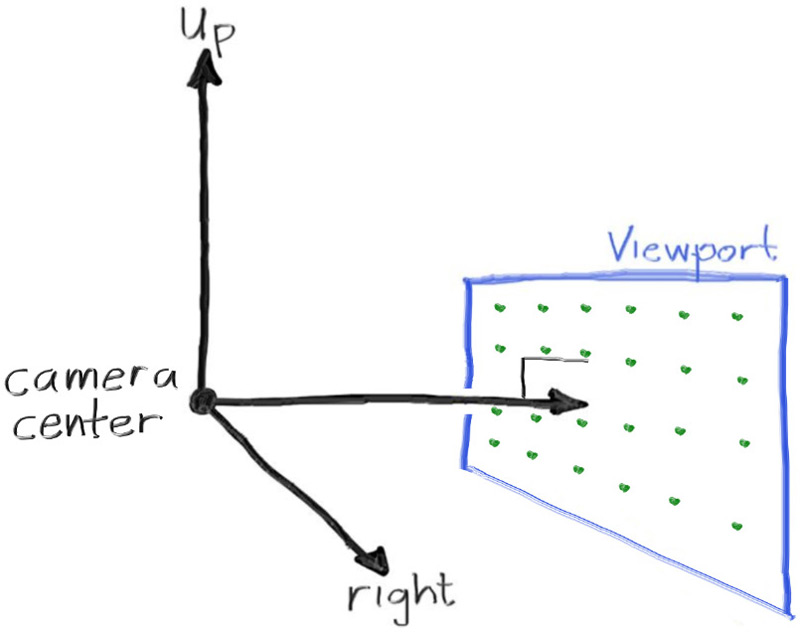
//确保视口的宽高比和图像的宽高比一样 auto focal_length = 1.0; auto viewport_height = 2.0; auto viewport_width = viewport_height * (double(image_width)/image_height); auto camera_center = point3(0,0,0);
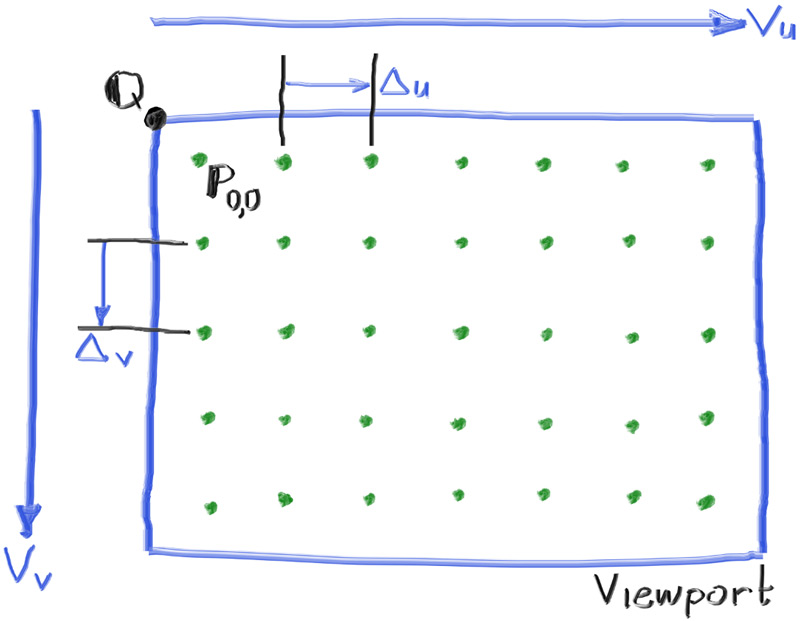
//设置视口向量与单位长度 auto viewport_u = vec3(viewport_width,0,0); auto viewport_v = vec3(0,-viewport_height,0); auto pixel_delta_u = viewport_u/image_width; auto pixel_delta_v = viewport_v/image_height;
//计算像素点位 auto viewport_upper_left = camera_center - vec3(0,0,focal_length) - viewport_v/2 - viewport_u/2; auto pixel00_loc = viewport_upper_left + 0.5*(pixel_delta_u+pixel_delta_v);
doublesize()const{ return max - min; } //闭区间 boolcontains(double x)const{ return min <= x && x <= max; } //开区间 boolsurrounds(double x)const{ return min < x && x < max; }
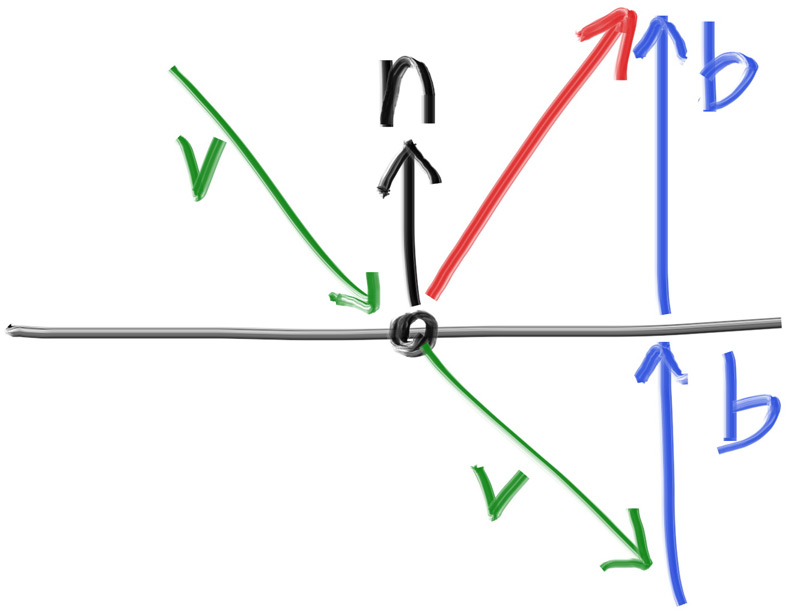
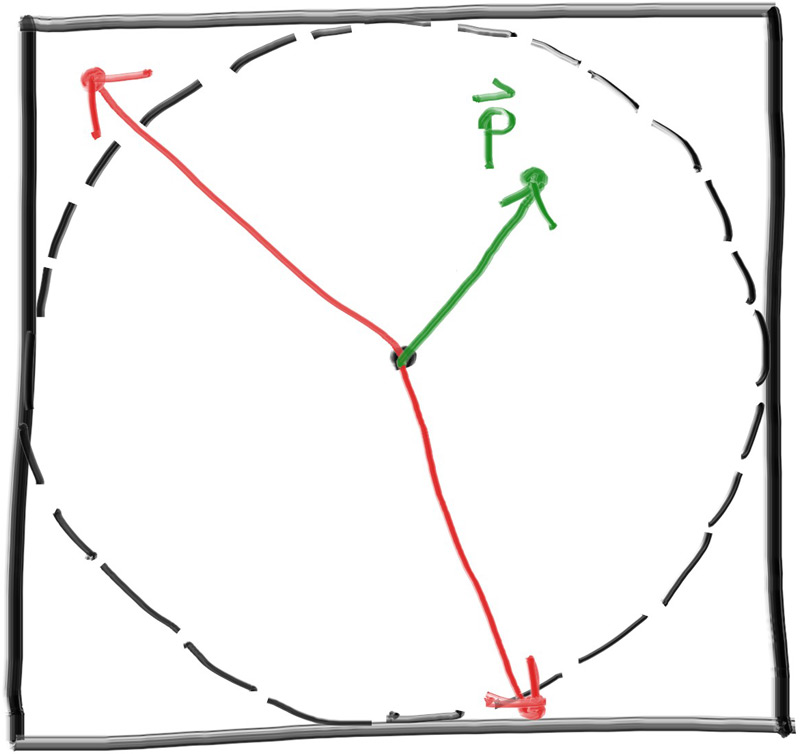
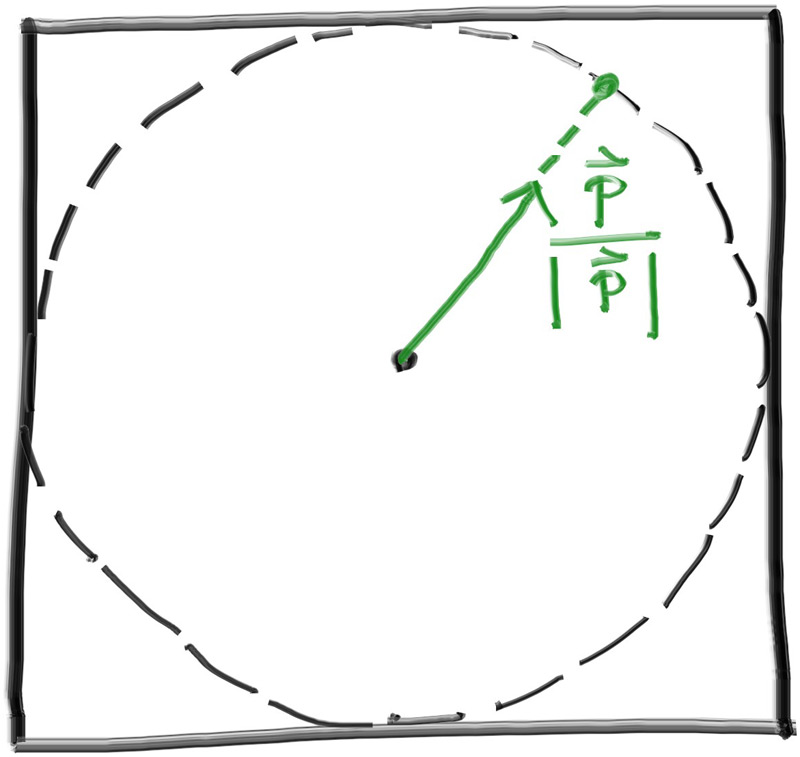
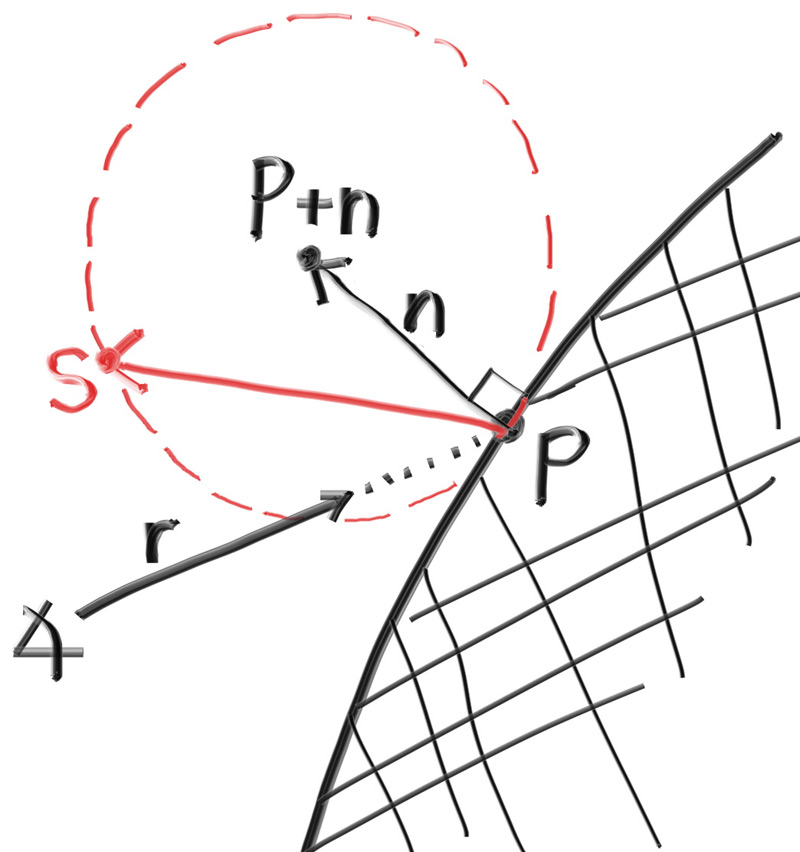
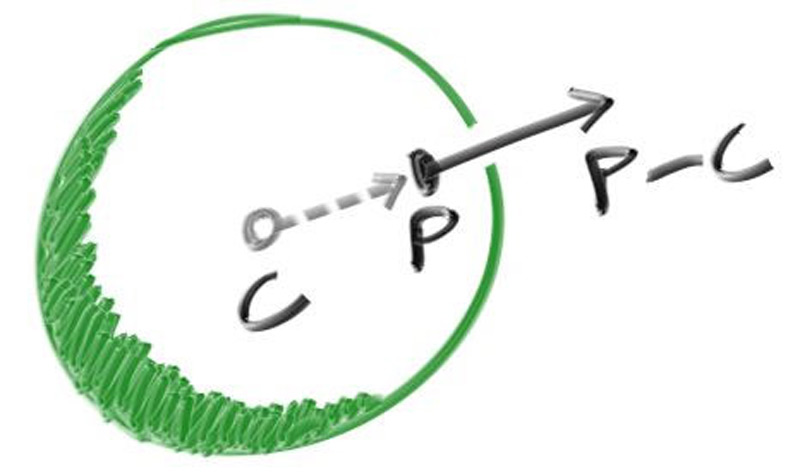
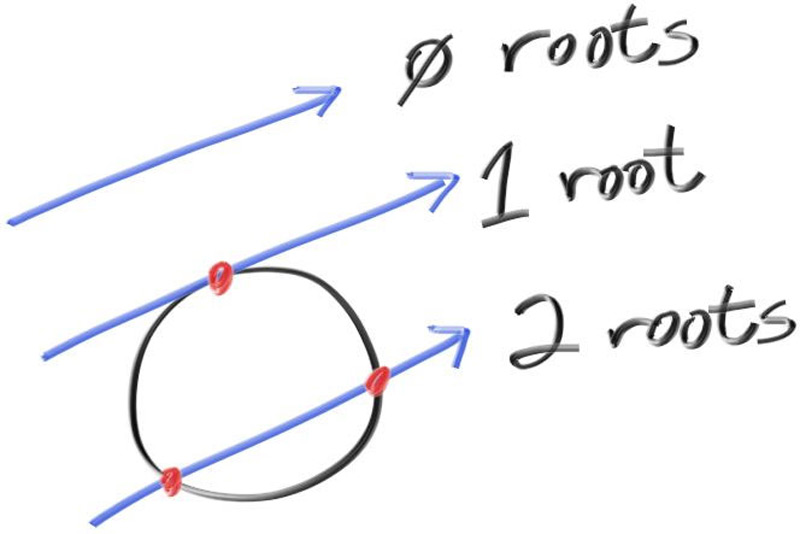
求解方程式: x = (-b +- sqrt(b^2 - 4*a*c))/(2*a) 根据联立方程式得到的数值: a = vec(d)*vec(d) b = -2*vec(d)*(point(C)-point(Q)) c = (point(C)-point(Q))*(point(C)-point(Q)) - r^2
boolhit_sphere(const point3& center,double radius,const ray& r){ vec3 oc = center - r.origin(); //计算(point(C)-point(Q)) auto a = dot(r.direction(),r.direction()); auto b = -2.0 * dot(r.direction(),oc); auto c = dot(oc,oc) - radius*radius; auto discriminant = b*b - 4*a*c; return (discriminant >= 0); }
color ray_color(ray & r){ if(hit_sphere(point3(0,0,-1),0.5,r)) return {1,0,0};
vec3 unit_direction = unit_vector(r.direction()); auto a = 0.5*(unit_direction.y() + 1.0); return (1.0-a)*color(1.0,1.0,1.0) + a*color(0.5,0.7,1.0); }
intmain(){ auto aspect_radio = 16.0/9.0; //长宽比 int image_width = 400;
//计算图像的高度,并确保图像的高度至少为1(单位长度) int image_height = int (image_width / aspect_radio); image_height = (image_height < 1) ? 1 : image_height;
//确保视口的宽高比和图像的宽高比一样 auto focal_length = 1.0; auto viewport_height = 2.0; auto viewport_width = viewport_height * (double(image_width)/image_height); auto camera_center = point3(0,0,0);
//设置视口向量与单位长度 auto viewport_u = vec3(viewport_width,0,0); auto viewport_v = vec3(0,-viewport_height,0); auto pixel_delta_u = viewport_u/image_width; auto pixel_delta_v = viewport_v/image_height;
//计算像素点位 auto viewport_upper_left = camera_center - vec3(0,0,focal_length) - viewport_v/2 - viewport_u/2; auto pixel00_loc = viewport_upper_left + 0.5*(pixel_delta_u+pixel_delta_v);