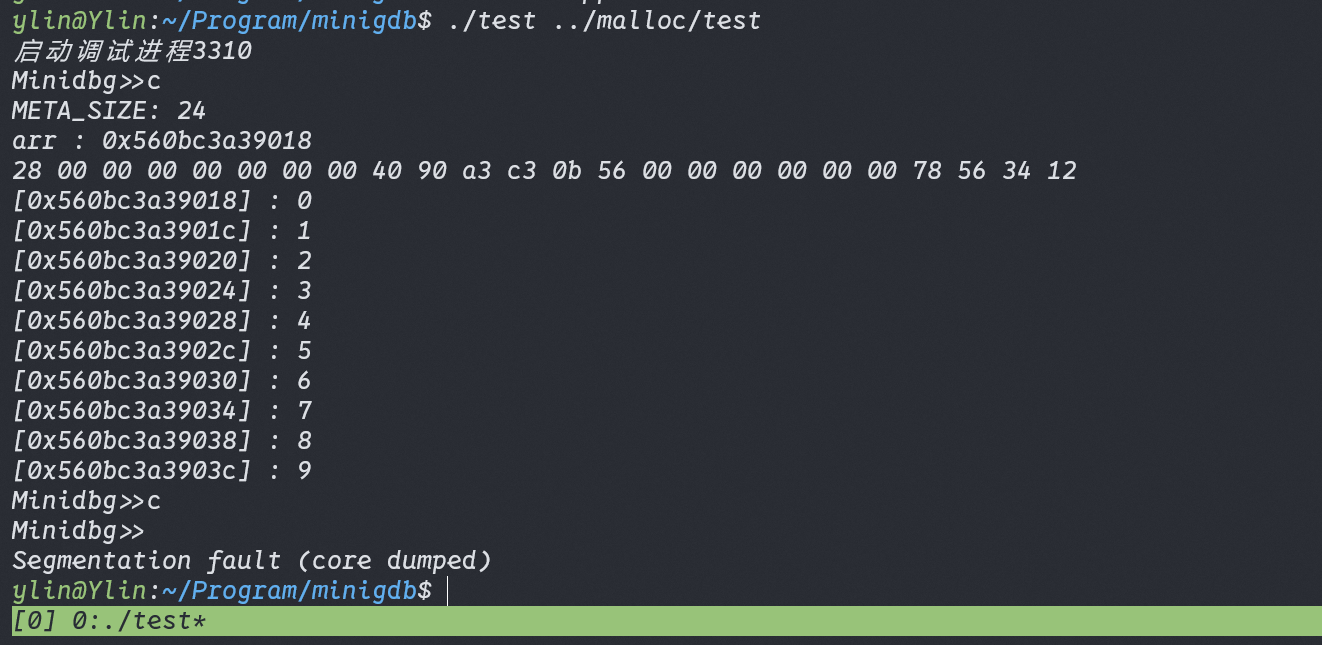
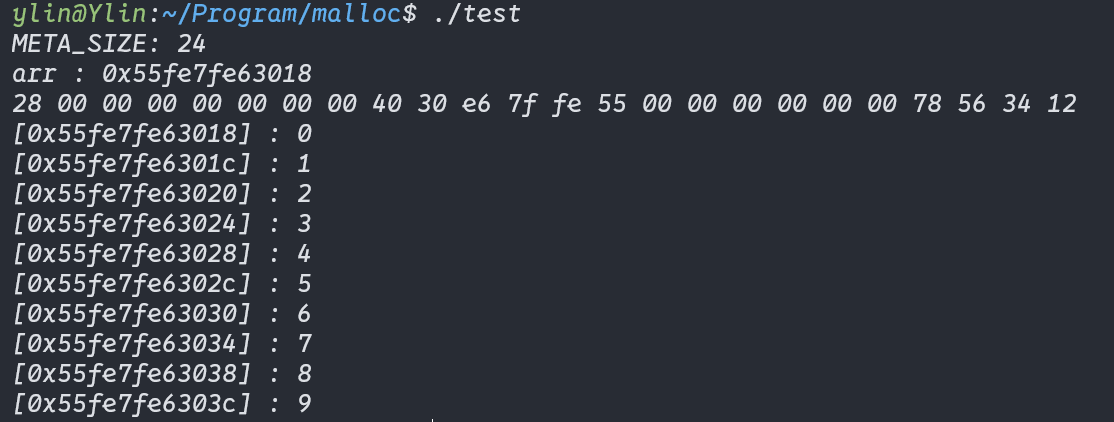
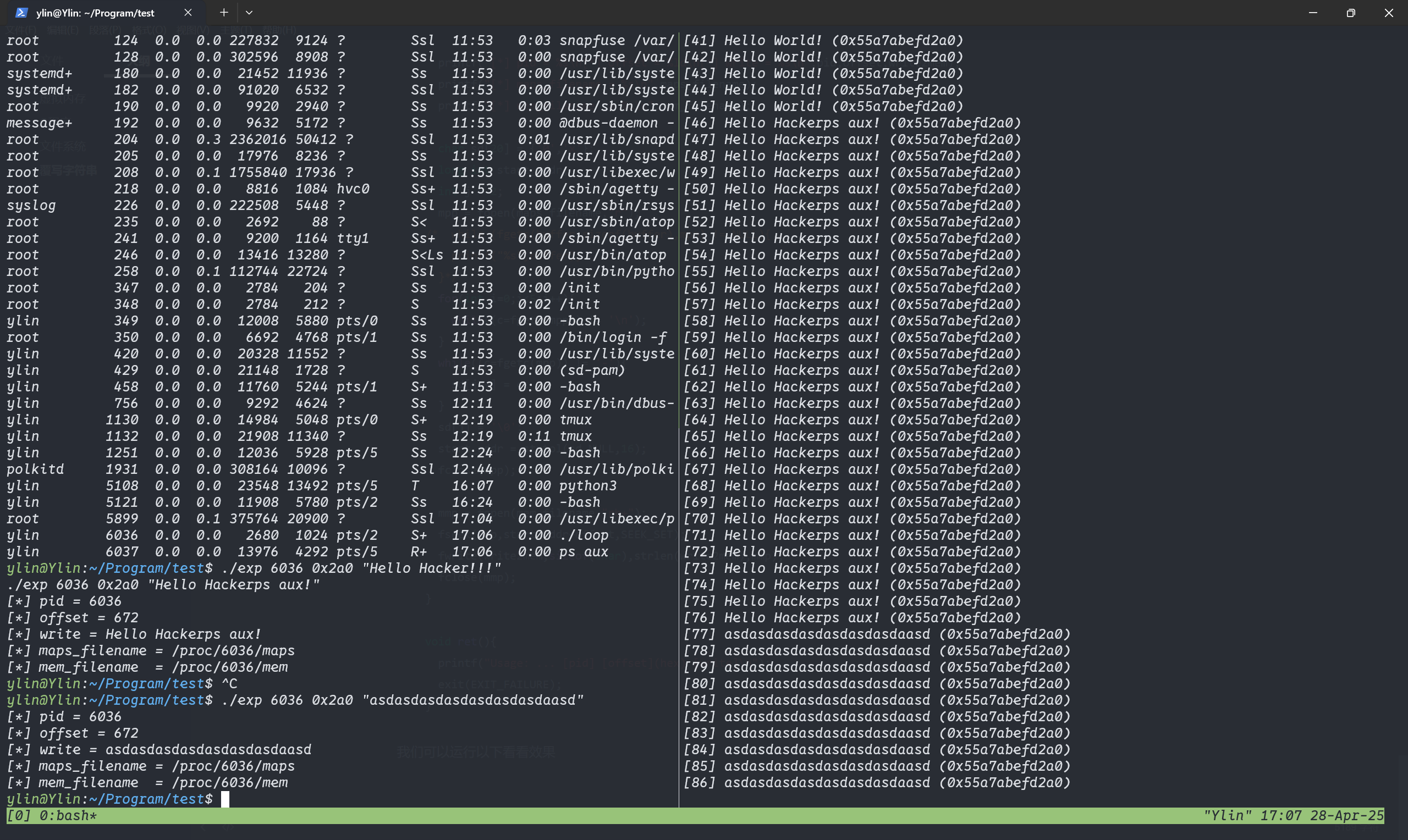
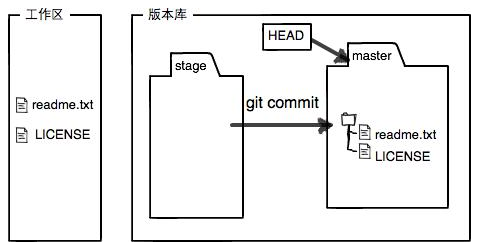
#!/usr/bin/env python3 ''' Locates and replaces the first occurrence of a string in the heap of a process Usage: ./read_write_heap.py PID search_string replace_by_string Where: - PID is the pid of the target process - search_string is the ASCII string you are looking to overwrite - replace_by_string is the ASCII string you want to replace search_string with '''
# get the pid from args pid = int(sys.argv[1]) if pid <= 0: print_usage_and_exit() search_string = str(sys.argv[2]) if search_string == "": print_usage_and_exit() write_string = str(sys.argv[3]) if search_string == "": print_usage_and_exit()
# open the maps and mem files of the process maps_filename = "/proc/{}/maps".format(pid) print("[*] maps: {}".format(maps_filename)) mem_filename = "/proc/{}/mem".format(pid) print("[*] mem: {}".format(mem_filename))
# try opening the maps file try: maps_file = open('/proc/{}/maps'.format(pid), 'r') except IOError as e: print("[ERROR] Can not open file {}:".format(maps_filename)) print(" I/O error({}): {}".format(e.errno, e.strerror)) sys.exit(1)
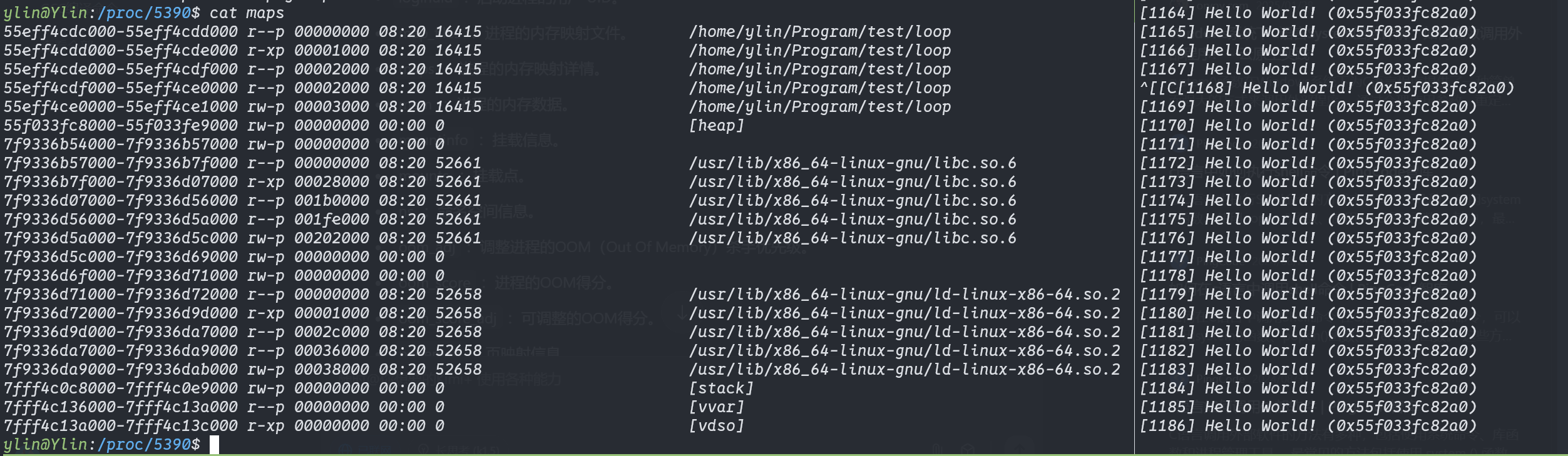
for line in maps_file: sline = line.split(' ') # check if we found the heap if sline[-1][:-1] != "[heap]": continue print("[*] Found [heap]:")
# check if there is read and write permission if perm[0] != 'r'or perm[1] != 'w': print("[*] {} does not have read/write permission".format(pathname)) maps_file.close() exit(0)
# get start and end of the heap in the virtual memory addr = addr.split("-") iflen(addr) != 2: # never trust anyone, not even your OS :) print("[*] Wrong addr format") maps_file.close() exit(1) addr_start = int(addr[0], 16) addr_end = int(addr[1], 16) print("\tAddr start [{:x}] | end [{:x}]".format(addr_start, addr_end))
# open and read mem try: mem_file = open(mem_filename, 'rb+') except IOError as e: print("[ERROR] Can not open file {}:".format(mem_filename)) print(" I/O error({}): {}".format(e.errno, e.strerror)) maps_file.close() exit(1)
$ ssh-keygen -t rsa -C "3280661240@qq.com" Generating public/private rsa key pair. Enter file inwhich to save the key (/home/ylin/.ssh/id_rsa): Created directory '/home/ylin/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/ylin/.ssh/id_rsa Your public key has been saved in /home/ylin/.ssh/id_rsa.pub The key fingerprint is: SHA256:7Y9JTYk3YxznFF9ODtZ5xak0GKB5t4Llw1eK/HRabBw 3280661240@qq.com The key's randomart image is: +---[RSA 3072]----+ | ...o +oB| | o . + X=| | o o .oE= =| | B.oo*B. | | .SBo=O*. | | .*==o | | oo. | | . + | | o . | +----[SHA256]-----+
$ git push -u origin master The authenticity of host 'github.com (140.82.112.4)' can't be established. ED25519 key fingerprint is SHA256:+DiY3wvvV6TuJJhbpZisF/zLDA0zPMSvHdkr4UvCOqU. This key is not known by any other names. Are you sure you want to continue connecting (yes/no/[fingerprint])? yes Warning: Permanently added 'github.com' (ED25519) to the list of known hosts. Enter passphrase for key '/home/ylin/.ssh/id_rsa': ------------------------------------ Enumerating objects: 22, done. Counting objects: 100% (22/22), done. Delta compression using up to 32 threads Compressing objects: 100% (14/14), done. Writing objects: 100% (22/22), 1.72 KiB | 1.72 MiB/s, done. Total 22 (delta 3), reused 0 (delta 0), pack-reused 0 remote: Resolving deltas: 100% (3/3), done. To github.com:Ylin07/Learn_Git.git * [new branch] master -> master branch 'master' set up to track 'origin/master'.
$ git merge n1 Auto-merging readme.txt CONFLICT (content): Merge conflict in readme.txt Automatic merge failed; fix conflicts and then commit the result.
结果提示了冲突,我们需要手动解决冲突后再提交,我们可以用git status告诉我们冲突的文件:
1 2 3 4 5 6 7 8 9 10 11
$ git status On branch master You have unmerged paths. (fix conflicts and run "git commit") (use "git merge --abort" to abort the merge)
Unmerged paths: (use "git add <file>..." to mark resolution) both modified: readme.txt
no changes added to commit (use "git add" and/or "git commit -a")
我们打开readme.txt看看:
1 2 3 4 5 6 7 8 9 10 11 12
Hello Git!!! I love you! Sorry I love her more. Please forgive me. The first modify. The second modify. Test new branch. <<<<<<< HEAD 56789 ======= 01234 >>>>>>> n1
Git
用<<<<<<<,=======,>>>>>>>标记出不同分支的内容,我们修改后再保存
我们修改之后再保存:
1 2 3 4 5 6 7 8
Hello Git!!! I love you! Sorry I love her more. Please forgive me. The first modify. The second modify. Test new branch. 00000
$ git status On branch master Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: readme.txt
no changes added to commit (use "git add" and/or "git commit -a")
$ git log --pretty=oneline da91da7e64267eb6f293ffc8b0bde18626777d58 (HEAD -> master) add sorry 20deae4e44bc6786110d3beeda5c86ba55b75f23 add my love 1428371d4f5f753c24e22e4311f6c11b3ff0656b wrote a read file
$ git log --pretty=oneline 20deae4e44bc6786110d3beeda5c86ba55b75f23 (HEAD -> master) add my love 1428371d4f5f753c24e22e4311f6c11b3ff0656b wrote a read file
$ git status On branch master Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: readme.txt
Untracked files: (use "git add <file>..." to include in what will be committed) LICENSE
no changes added to commit (use "git add" and/or "git commit -a")
$ git add readme.txt $ git status On branch master Changes to be committed: (use "git restore --staged <file>..." to unstage) modified: readme.txt
然后我们再进行一次修改,接着我们直接提交到仓库:
1 2 3 4 5 6 7 8 9 10 11
$ git commit -m "git tracks change" [master c34bcbc] git tracks change 1 file changed, 1 insertion(+) $ git status On branch master Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: readme.txt
no changes added to commit (use "git add" and/or "git commit -a")
现在我们可以使用git diff HEAD -- readme.txt查看工作区和版本库中的最新版本的区别:
1 2 3 4 5 6 7 8 9 10
$ git diff HEAD -- readme.txt diff --git a/readme.txt b/readme.txt index 0394257..135beba 100644 --- a/readme.txt +++ b/readme.txt @@ -3,3 +3,4 @@ I love you! Sorry I love her more. Please forgive me. The first modify. +The second modify.
$ git status On branch master Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: readme.txt
no changes added to commit (use "git add" and/or "git commit -a")
这里提到可以使用git restore <file>...恢复工作区到暂存区的状态。
1 2 3 4 5 6 7 8 9 10 11 12
$ git status On branch master Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: readme.txt
no changes added to commit (use "git add" and/or "git commit -a") $ git restore readme.txt $ git status On branch master nothing to commit, working tree clean
$ git status On branch master Changes to be committed: (use "git restore --staged <file>..." to unstage) modified: readme.txt
$ git restore --staged -- readme.txt $ git status On branch master Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: readme.txt
no changes added to commit (use "git add" and/or "git commit -a") ylin@Ylin:~/Program/learn_git$
我们成功的撤销了暂存区的内容,接着我们再次撤销工作区的修改:
1 2 3 4
$ git restore readme.txt $ git status On branch master nothing to commit, working tree clean
现在我们实现了对工作区和暂存区的撤回操作
版本库撤销
即版本回退,见上。
删除文件
在git中,删除也是一个修改操作,我们可以进行尝试。
我们向创建一个新文件test.txt并提交
1 2 3 4 5
$ git add test.txt $ git commit -m "A test" [master f940b04] A test 1 file changed, 1 insertion(+) create mode 100644 test.txt
然后我将其从工作区中删除,再使用git status查看状态:
1 2 3 4 5 6 7 8 9
$ rm test.txt $ git status On branch master Changes not staged for commit: (use "git add/rm <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) deleted: test.txt
no changes added to commit (use "git add" and/or "git commit -a")
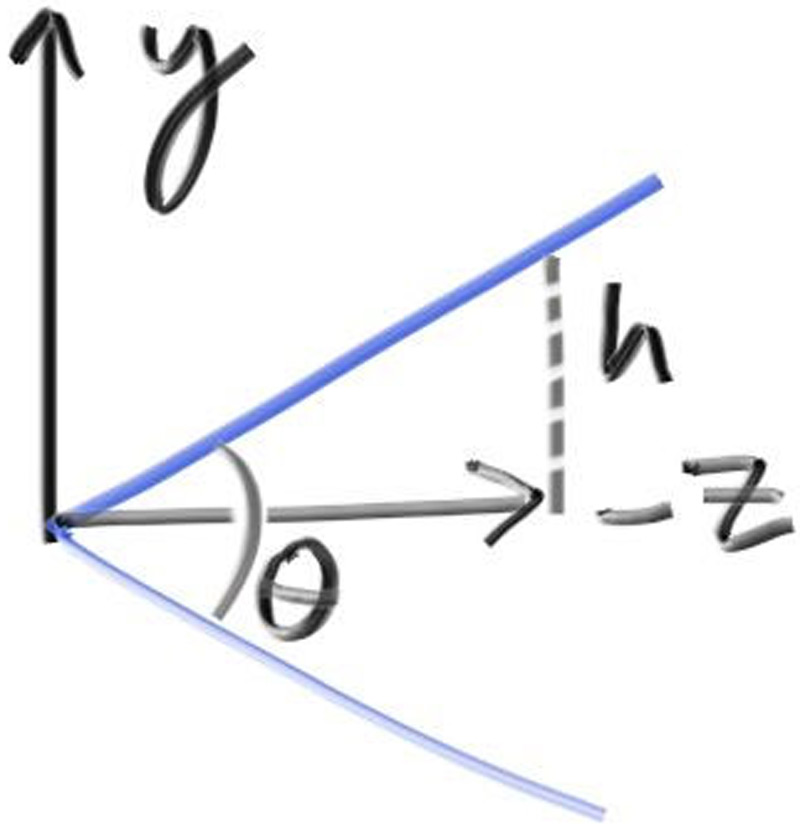
//确认视窗的设置 auto focal_length = 1.0; //焦距设置 auto theta = degree_to_radius(vfov); auto h = std::tan(theta/2); auto viewport_height = 2*h*focal_length; auto viewport_width = viewport_height*(double (image_width)/image_height);
//视图边缘的向量计算 auto viewport_u = vec3(viewport_width,0,0); auto viewport_v = vec3(0,-viewport_height,0); //计算视图的像素间的水平竖直增量 pixel_delta_u = viewport_u/image_width; pixel_delta_v = viewport_v/image_height;
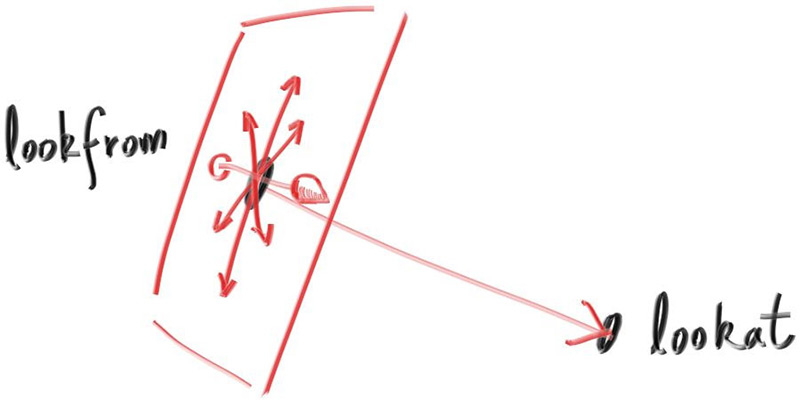
//确认视窗的设置 auto focal_length = (lookfrom - lookat).length(); //焦距设置 auto theta = degree_to_radius(vfov); auto h = std::tan(theta/2); auto viewport_height = 2*h*focal_length; auto viewport_width = viewport_height*(double (image_width)/image_height);
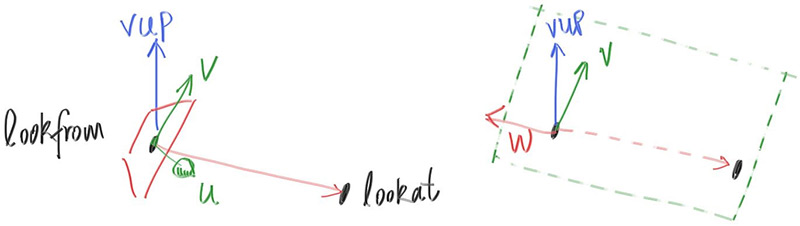
//计算摄像机的相对基底 w = unit_vector(lookfrom-lookat); u = unit_vector(cross(vup,w)); v = cross(w,u);;
//视图边缘的向量计算 auto viewport_u = viewport_width * u; auto viewport_v = viewport_height * -v; //计算视图的像素间的水平竖直增量 pixel_delta_u = viewport_u/image_width; pixel_delta_v = viewport_v/image_height;
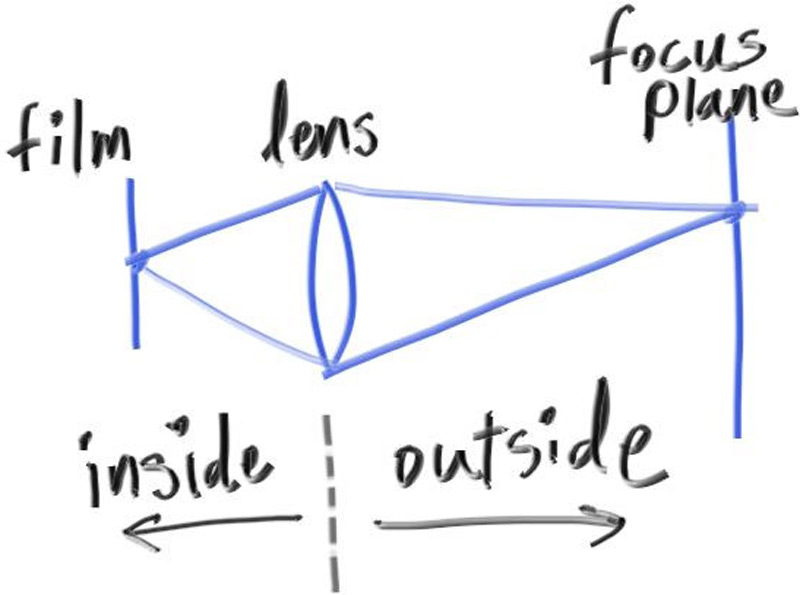
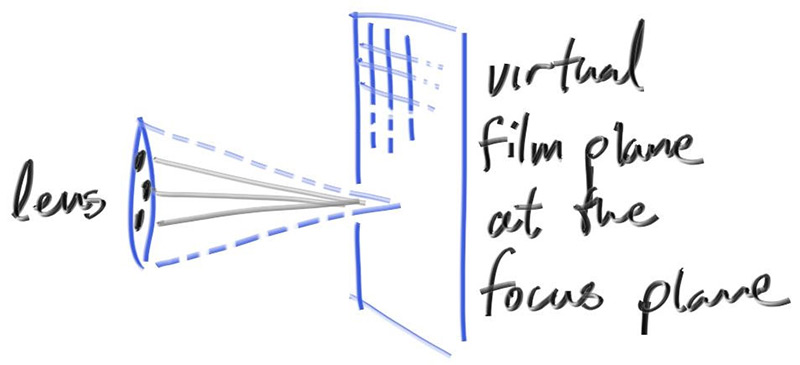
//确认视窗的设置 // auto focal_length = (lookfrom - lookat).length(); //焦距设置 auto theta = degree_to_radius(vfov); auto h = std::tan(theta/2); auto viewport_height = 2*h*focus_dist; //确保视口和焦点平面重合 auto viewport_width = viewport_height*(double (image_width)/image_height);
//计算摄像机的相对基底 w = unit_vector(lookfrom-lookat); u = unit_vector(cross(vup,w)); v = cross(w,u);
//视图边缘的向量计算 auto viewport_u = viewport_width * u; auto viewport_v = viewport_height * -v; //计算视图的像素间的水平竖直增量 pixel_delta_u = viewport_u/image_width; pixel_delta_v = viewport_v/image_height;