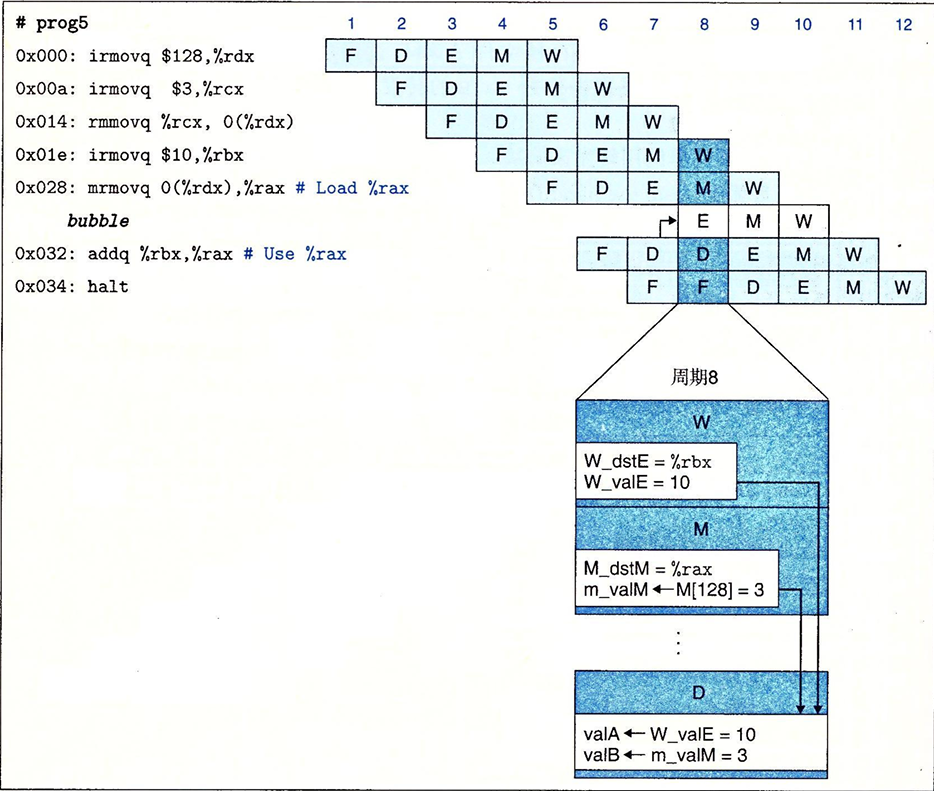
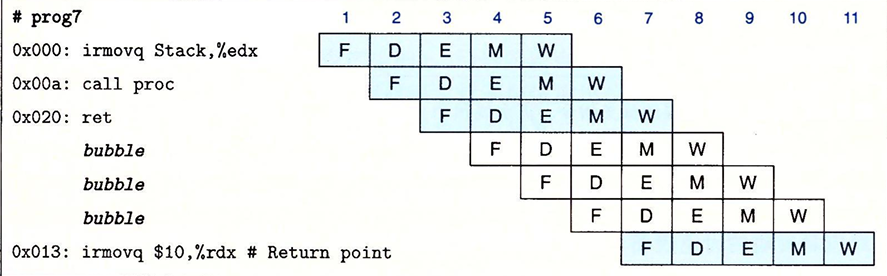
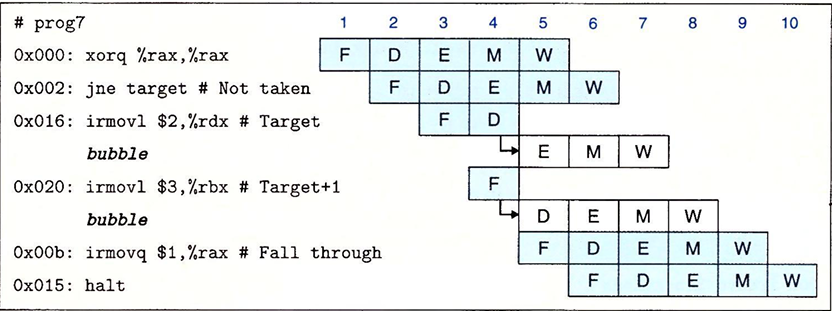
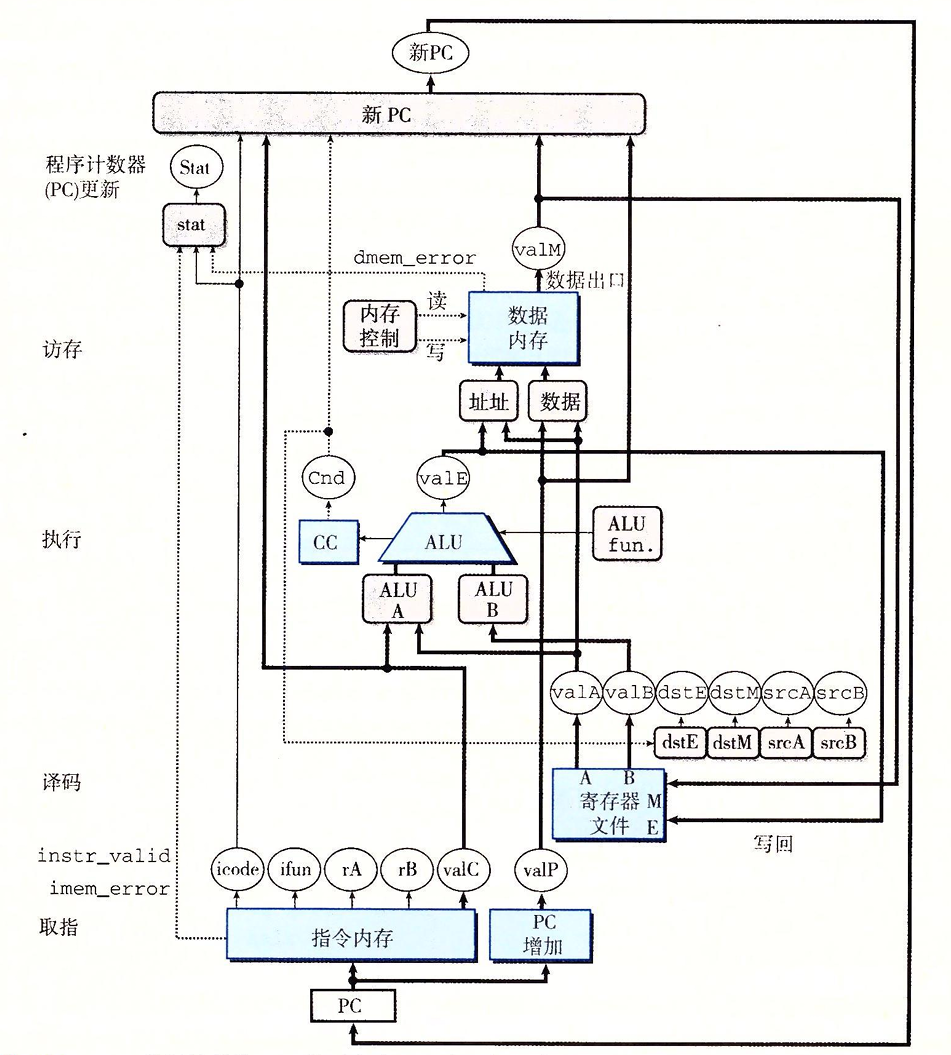
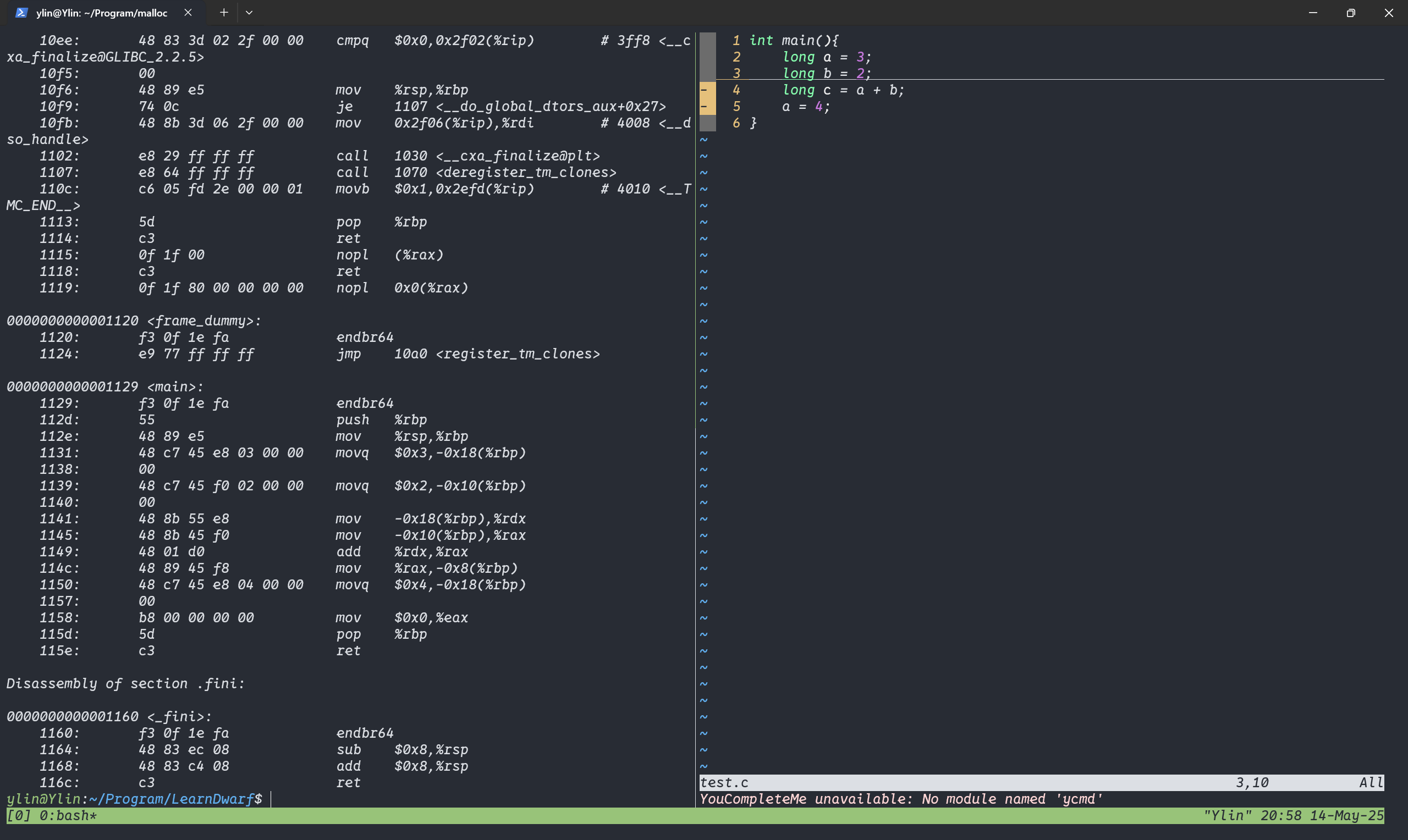
一下子就到七月了,我六月的总结并没有写,因为六月比较忙…前半个月急着复习。后半个月忙着玩儿和打游戏。
上次说这个学期希望绩点高一点,我对这个学期的绩点还算比较满意吧,好歹花了很多时间精力在上面。然后是时长两周的小学期,感觉还是很不错的,前端的基础知识稍微巩固了一下,同时学习了很多新的东西,相较于刚开学的时候自己学前端,现在很多思路就很清晰。项目实践也比较容易上手。最有意思的是接触了一下XSS漏洞,发现网络安全也是很有意思的,并没有想象中的那么难,感觉是一个很好的上手点。
然后就是联系了一位老师做我的导师,他的方向是混沌密码学,他建议我尝试将混沌密码学用于图像编码,以此作为研究方向。让我去研究一些相关的知识和阅读其他的论文。但是感觉我的数学和英语基础还是比较薄弱,这样也是我需要加强的地方。
接下来的话,做下暑假的安排吧,我就先规划一下七月的,八月的之后再说:
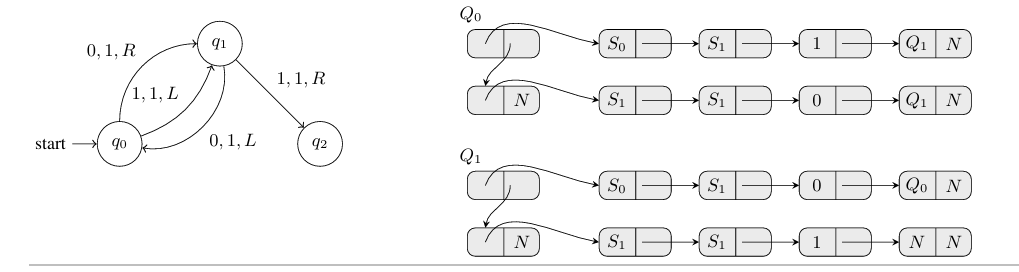
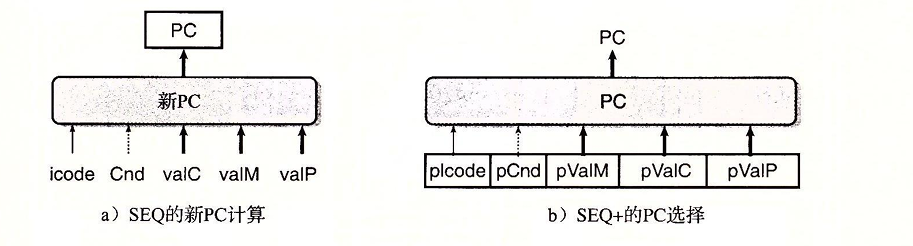
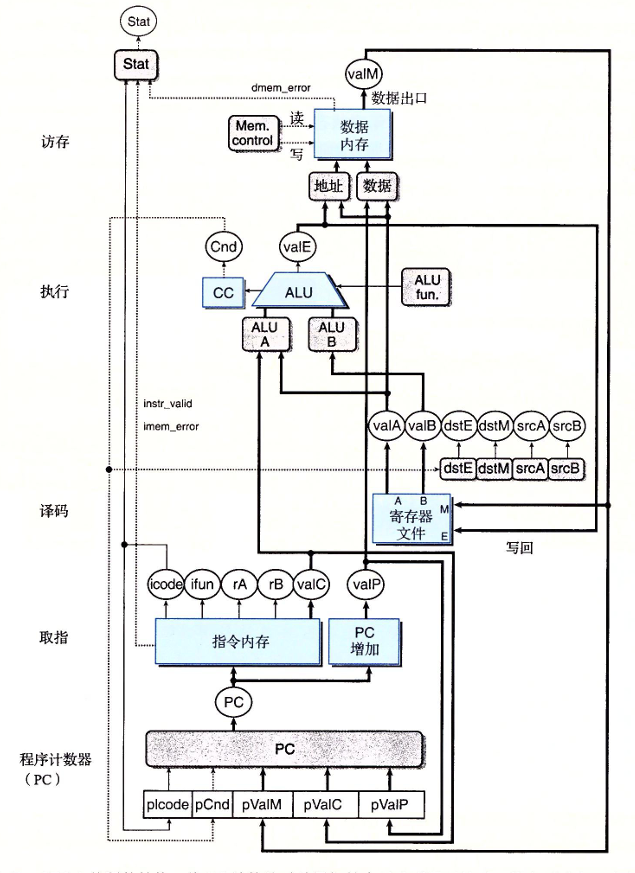
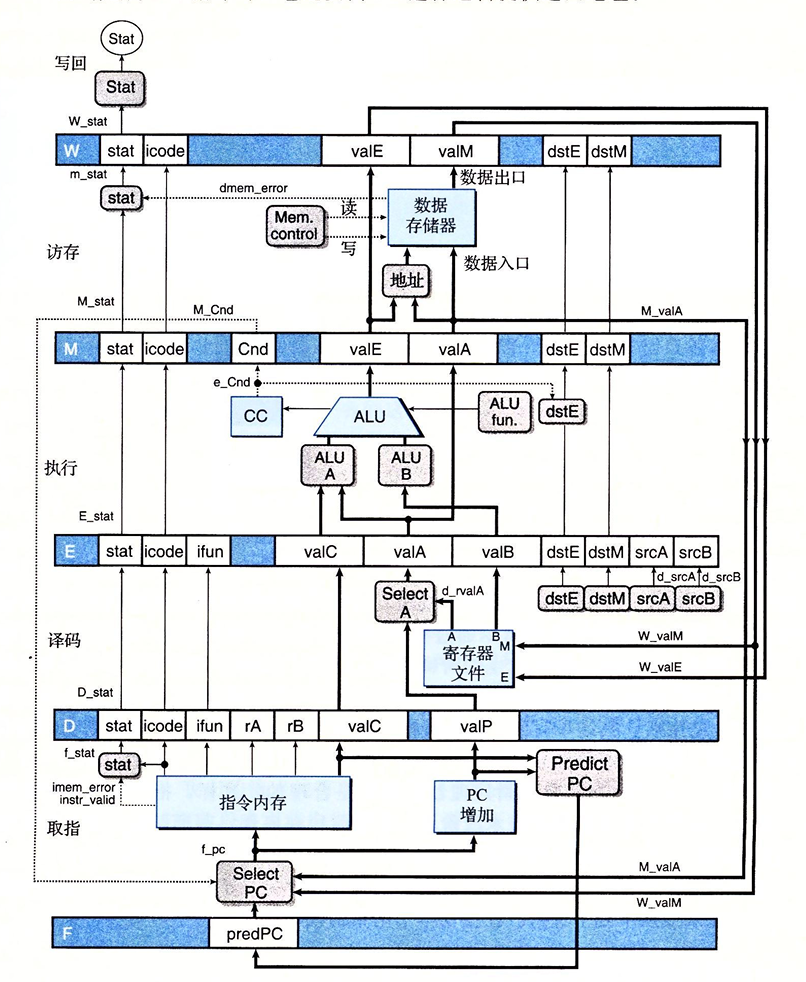
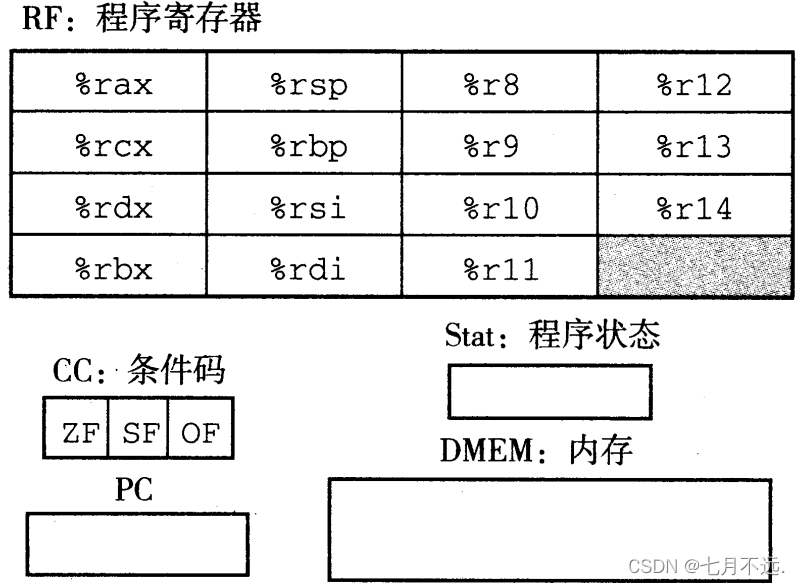
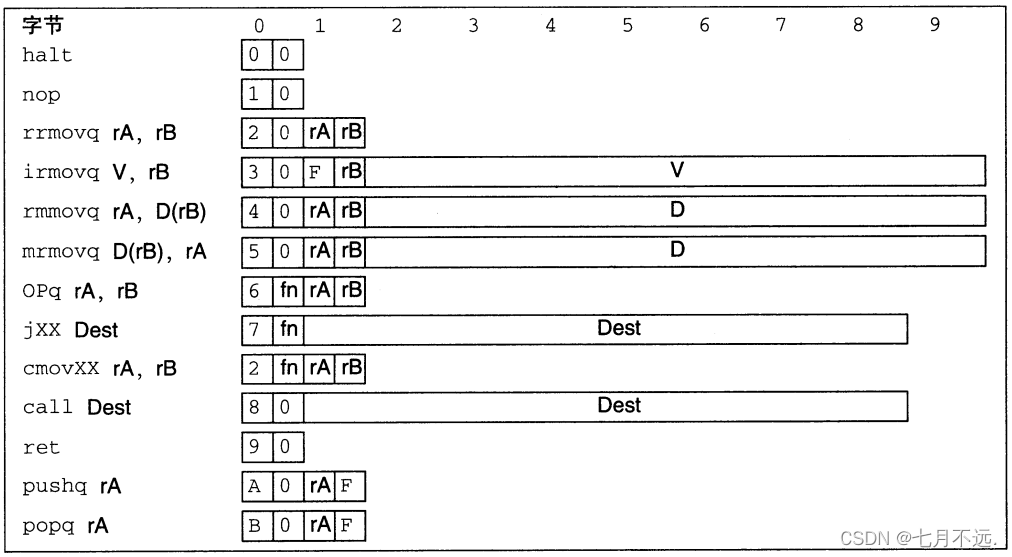
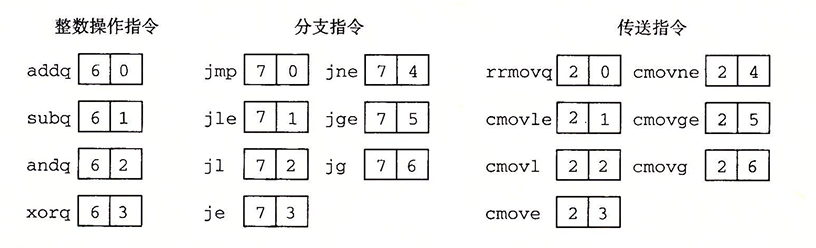
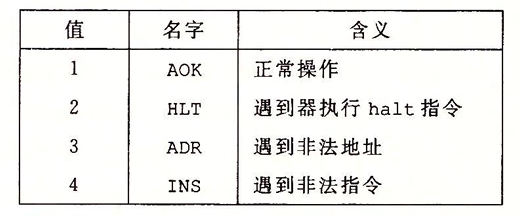
- 首先是CSAPP的学习从现在开始的一周内,至少要学到第七章链接。
- 然后是接下来时间争取能学完第九章,在八月份之前。
- 平时累了的时候要着手开始学习算法,目前的打算是跟着OIwiki入门,争取每天写2~5题,学一个新的知识点
- 在时间有多的情况下,要开始学习Java,因为之后的很多知识都不可避免的要用到它
- 坚持每天都要背单词,先把四级背完
- 然后是这个月要把科目二结束,争取下个月可以把科目三过完
感觉暑假要做的事情很多,当然,可以做的事情也很多。要抓住这个机会,提升强化基本功能力,好迎接下个学期大量的专业课程和专业知识。加油呀相信自己。
我有时候也会在想自己为什么要学的这么辛苦,是因为喜欢吗,是为了更优秀一点吗。可能都有吧,关键是我想这么做,也许想学的时候也会学一学吧,想玩的时候也会好好玩一下吧。也许我的目标和规划做的到,也许做不到。但是没关系,我想这么做就行了。