ylin@Ylin:~/Program/test$ gcc test.c -o test -Wall -Og /usr/bin/ld: /tmp/ccKOmx5V.o: in function `main': test.c:(.text+0xe): undefined reference to `foo'
ylin@Ylin:~/Program/test$ gcc -o prog 1.c 2.c /usr/bin/ld: /tmp/ccYSd6rb.o: in function `main': 2.c:(.text+0x0): multiple definition of `main'; /tmp/ccogxBxO.o:1.c:(.text+0x0): first defined here collect2: error: ld returned 1 exit status
这是因为强符号main被定义了多次,造成了冲突。下面也是
1 2 3 4 5 6 7 8 9 10
//1.c int x=114; intmain(){ return0; } //2.c int x=514; intf(){ return0; }
1 2 3
ylin@Ylin:~/Program/test$ gcc -o prog 1.c 2.c /usr/bin/ld: /tmp/cc9GFQfr.o:(.data+0x0): multiple definition of `x'; /tmp/ccljmBRr.o:(.data+0x0): first defined here collect2: error: ld returned 1 exit status
这里是因为被初始化的全局变量(强符号)x出现了多次,造成冲突。
规则二
1 2 3 4 5 6 7 8 9 10 11 12 13 14
//1.c #include<stdio.h> int x=114; intmain(){ f(); printf("%d\n",x); return0; } //2.c int x; intf(){ x = 514; return0; }
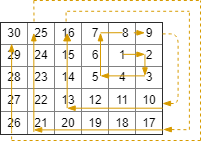
constint DIR[4][2] = {{0,1},{1,0},{0,-1},{-1,0}}; vector<vector<int>> spiralMatrixIII(int rows, int cols, int rStart, int cStart) { vector<vector<int>> ans; int total = rows*cols; int num = 1; int i = rStart,j = cStart; //令i,j记录路径的实时位置 int left = cStart - 1,right = cStart + 1,top = rStart - 1,bottom = rStart + 1; //确定边界 int dir=0; //记录方向 while(num <= total){ if(i>=0&&i<rows&&j>=0&&j<cols){ //当路径到达矩阵内部时,记录当前位置 ans.push_back({i,j}); num++; } if(dir==0&&j==right){ //如果向右移动触碰右边界 dir+=1; //则转向 right++; //并拓展右边界 }elseif(dir==1&&i==bottom){ //如果向下移动触碰下边界 dir+=1; //则转向 bottom++; //并拓展下边界 }elseif(dir==2&&j==left){ //... dir+=1; left--; }elseif(dir==3&&i==top){ //... dir=0; top--; } i += DIR[dir][0]; //根据方向来更新位置 j += DIR[dir][1]; } return ans; }
规律法
我们可以观察螺线路径的一个显著规律:每转向两次会更新一次前进的步长
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
constint DIR[4][2] = {{0, 1}, {1, 0}, {0, -1}, {-1, 0}}; vector<vector<int>> spiralMatrixIII(int R, int C, int r0, int c0) { int num=0; int dir=0; int run=2; //步长计数器 vector<vector<int>> ans;
while(num < R * C){ for(int i = 0; i < run / 2; i ++){ //遍历步长,每转两下就会增加一步 if(r0 >= 0 && r0 < R && c0 >= 0 && c0 < C) ans.push_back({r0, c0}), ++ num; r0 += DIR[dir][0]; c0 += DIR[dir][1]; } pos = (pos + 1) % 4; //每遍历一次步长,就转向 run++; //利用取整的性质,每转向两次才会增加一次步长 } return ans; }
intlower_bound(vector<int> arr, int target){ left = 0; right = arr.size() - 1; while (left <= right){ int mid = left + (right-left)>>1; if (arr[mid] < target) left = mid + 1; else: right = mid -1; } return left; }
classSolution { public: vector<int> searchRange(vector<int>& nums, int target){ int left = lower_bound(nums,target); if(nums.empty() || left == nums.size() || nums[left]!=target ){ //当left==len(nums)时,说明数组中没有>=target的数 return vector<int>{-1,-1}; } int right = lower_bound(nums,target+1)-1; return vector<int>{left,right};
} //返回>=target的第一个数 intlower_bound(vector<int>& nums,int target){ int start = 0; int end = nums.size() - 1; while (start <= end){ int mid = (end - start)/2 + start; if(nums[mid] < target){ start = mid + 1; }else{ end = mid -1; } } return start; } };
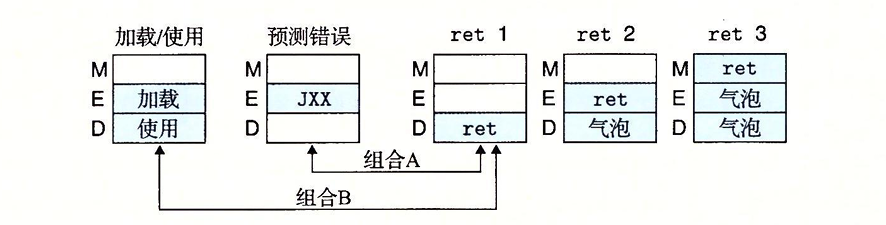
# F_stall # 加载/使用冒险 if (E_icode in [MRMOVQ,POPQ] and E_dstM in [d_srcA,d_srcB]): F_stall = 1 # ret处理 elseif RET in [D_icode,E_icode,M_icode]: F_stall = 1 # D_stall # 加载/使用冒险 if (E_icode in [MRMOVQ,POPQ] and E_dstM in [d_srcA,d_srcB]): D_stall = 1
# D_bubble # 排除组合状态 ifnot (E_icode in [MRMOVQ,POPQ] and E_dstM in [d_srcA,d_srcB]): if RET in [D_icode,E_icode,M_icode]: D_bubble = 1 # 分支预测错误 elseif E_icode == JXX && !e_Cnd: D_bubble
# E_bubble # 分支预测错误 if E_icode == JXX && !e_Cnd: E_bubble = 1 # 加载/冒险使用 elseif (E_icode in [MRMOVQ,POPQ] and E_dstM in [d_srcA,d_srcB]): E_bubble = 1
同时为了避免异常后的指令更新了程序状态,我们设置条件码不被整数操作设置:
1 2 3 4
# set_cc if E_icode == OPq: if (not m_stat in [SADR,SINS,SHLT] andnot W_stat in [SADR,SINS,SHLT]): set_CC = 1