auto ground_material = make_shared<lambertian>(color(0.5, 0.5, 0.5)); world.add(make_shared<sphere>(point3(0,-1000,0), 1000, ground_material));
for (int a = -8; a < 8; a++) { for (int b = -8; b < 8; b++) { auto choose_mat = random_double(); point3 center(a + 0.9*random_double(), 0.2, b + 0.9*random_double());
ylin@Ylin:~/Program/test$ make cat a.txt b.txt > m.txt cat m.txt c.txt > x.txt ylin@Ylin:~/Program/test$ ls a.txt b.txt c.txt Makefile m.txt x.txt ylin@Ylin:~/Program/test$ cat x.txt I am a.txt I am b.txt I am c.txt ylin@Ylin:~/Program/test$ cat m.txt I am a.txt I am b.txt ylin@Ylin:~/Program/test$
ylin@Ylin:~/Program/test$ make cat m.txt c.txt > x.txt ylin@Ylin:~/Program/test$ cat x.txt I am a.txt I am b.txt I am c.txt (modified) ylin@Ylin:~/Program/test$
ylin@Ylin:~/Program/test$ make no_output not display echo 'will display' will display
控制错误
make在执行命令时,会检查每一条命令的返回值,如果返回值错误,就会中断执行。
例如我们手动构建一个错误(用rm删除一个不存在的文件):
1 2 3
has_error: rm zzz.txt echo 'OK'
会发生:
1 2 3 4
ylin@Ylin:~/Program/test$ make has_error rm zzz.txt rm: cannot remove 'zzz.txt': No such file or directory make: *** [Makefile:25: has_error] Error 1
但是有时候我们希望忽略错误,我们可以在特定的指令前面加上-用来忽略错误的命令:
1 2 3
ignore_error: -rm zzz.txt echo 'ok'
输出结果如下:
1 2 3 4 5 6
ylin@Ylin:~/Program/test$ make ignore_error rm zzz.txt rm: cannot remove 'zzz.txt': No such file or directory make: [Makefile:29: ignore_error] Error 1 (ignored) echo 'ok' ok
ylin@Ylin:~/Program/test$ make Compiling hello.c to hello.o cc -c hello.c -o hello.o Compiling main.c to main.o cc -c main.c -o main.o cc -o a.out hello.o main.o
if (!make_token(e)) { *success = false; return0; }
/* TODO: Implement code to evaluate the expression. */ for (i = 0; i < nr_token; i ++) { // certain type 视具体情况而定 if (tokens[i].type == '*' && (i == 0 || tokens[i - 1].type == certain type) ) { tokens[i].type = DEREF; } }
staticboolmake_token(char *e) { int position = 0; int i; int index=0; regmatch_t pmatch; nr_token = 0; while (e[position] != '\0') { /* Try all rules one by one. */ for (i = 0; i < NR_REGEX; i ++) { if (regexec(&re[i], e + position, 1, &pmatch, 0) == 0 && pmatch.rm_so == 0) { char *substr_start = e + position; int substr_len = pmatch.rm_eo; Log("match rules[%d] = \"%s\" at position %d with len %d: %.*s", i, rules[i].regex, position, substr_len, substr_len, substr_start); position += substr_len; /* TODO: Now a new token is recognized with rules[i]. Add codes * to record the token in the array `tokens'. For certain types * of tokens, some extra actions should be performed. */ switch (rules[i].token_type) { case TK_NUM: tokens[index].type = rules[i].token_type; for(int j=0;j<substr_len;j++) tokens[index].str[j] = substr_start[j]; // printf("The num is %s\n",tokens[index].str); break; default: tokens[index].type = rules[i].token_type; } index++; break; } } if (i == NR_REGEX) { printf("no match at position %d\n%s\n%*.s^\n", position, e, position, ""); returnfalse; } } returntrue; }
eval(p, q) { if (p > q) { /* Bad expression */ } elseif (p == q) { /* Single token. * For now this token should be a number. * Return the value of the number. */ } elseif (check_parentheses(p, q) == true) { /* The expression is surrounded by a matched pair of parentheses. * If that is the case, just throw away the parentheses. */ return eval(p + 1, q - 1); } else { /* We should do more things here. */ } }
eval(p, q) { if (p > q) { /* Bad expression */ } elseif (p == q) { /* Single token. * For now this token should be a number. * Return the value of the number. */ } elseif (check_parentheses(p, q) == true) { /* The expression is surrounded by a matched pair of parentheses. * If that is the case, just throw away the parentheses. */ return eval(p + 1, q - 1); } else { op = the position of 主运算符 in the token expression; val1 = eval(p, op - 1); val2 = eval(op + 1, q);
/* extract the first token as the command */ char *cmd = strtok(str, " "); if (cmd == NULL) { continue; }
/* treat the remaining string as the arguments, * which may need further parsing */ char *args = cmd + strlen(cmd) + 1; if (args >= str_end) { args = NULL; }
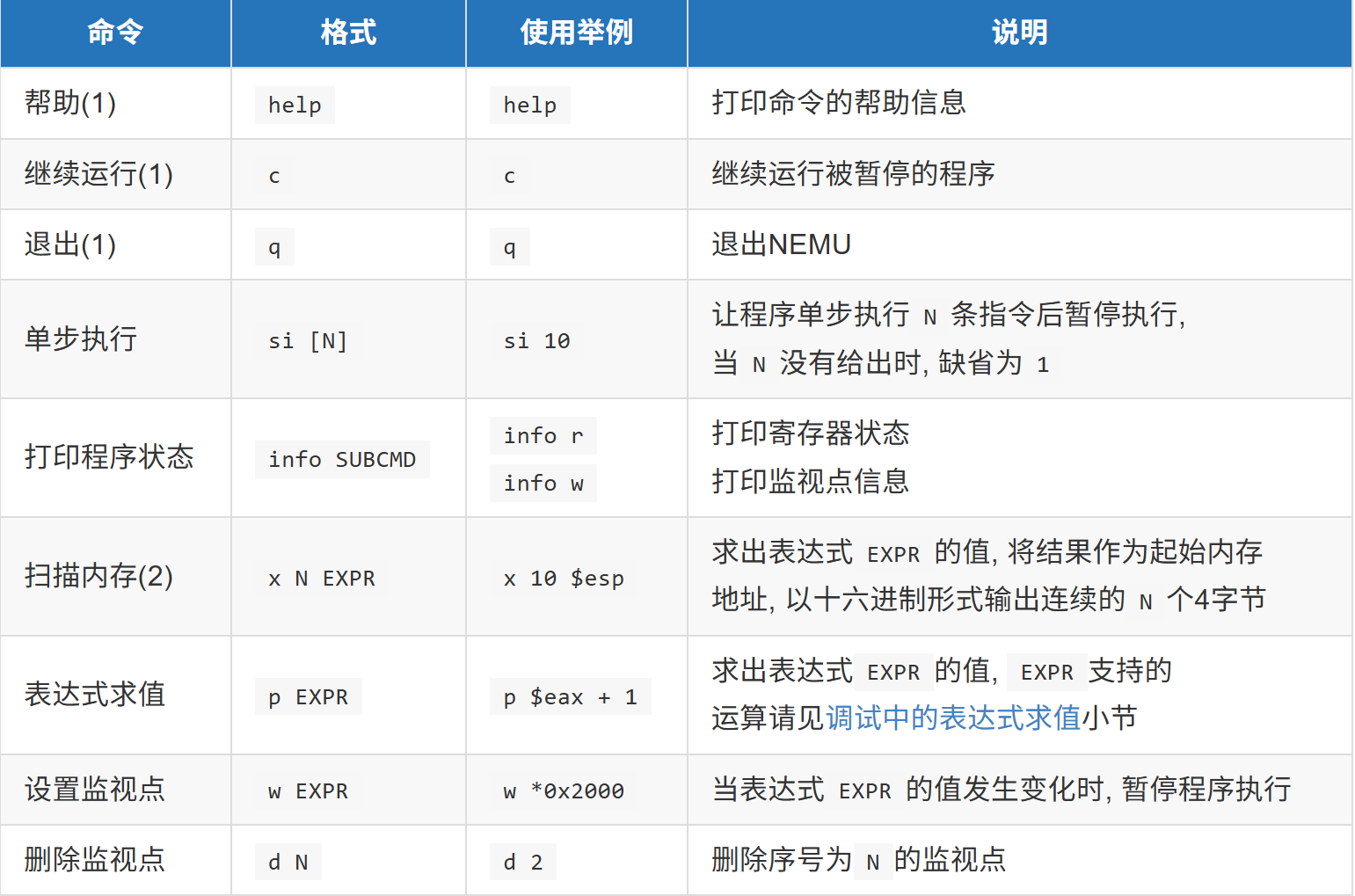
cmd_table [] = { { "help", "Display information about all supported commands", cmd_help }, { "c", "Continue the execution of the program", cmd_c }, { "q", "Exit NEMU", cmd_q },
ylin@Ylin:~/ics2025/nemu$ make run /home/ylin/ics2025/nemu/build/riscv32-nemu-interpreter --log=/home/ylin/ics2025/nemu/build/nemu-log.txt [src/utils/log.c:30 init_log] Log is written to /home/ylin/ics2025/nemu/build/nemu-log.txt [src/memory/paddr.c:50 init_mem] physical memory area [0x80000000, 0x87ffffff] [src/monitor/monitor.c:51 load_img] No image is given. Use the default build-in image. [src/monitor/monitor.c:28 welcome] Trace: ON [src/monitor/monitor.c:29 welcome] If trace is enabled, a log file will be generated to record the trace. This may lead to a large log file. If it is not necessary, you can disable it in menuconfig [src/monitor/monitor.c:32 welcome] Build time: 20:11:21, Sep 26 2025 Welcome to riscv32-NEMU! For help, type "help" (nemu) q make: *** [/home/ylin/ics2025/nemu/scripts/native.mk:38: run] Error 1