找到一个比较好的项目Byterun,这里进行一下复现。
Byterun
Byterun
是一个基于Python实现的Python字节码解释器,简化了Cpython的实现,展示了Python解释器在底层上的实现原理,以及相关的组织过程。
搭建一个解释器
解释器本质上就是一个虚拟机,他会对你产生的字节码信息进行解释,然后基于栈运行,实现运算、分支条件、循环结构等功能。
Python解释器实际上就是一个字节码解释器,它接受字节码,然后输出运行结果。当你写下一段Python代码时,会被词法分析器解析为token流,然后通过语法分析和编译器,作为字节码(code
object)进行输出。然后字节码再由Python解释器进行运行。这里字节码的作用有点像汇编语言在C语言编译过程。
微型解释器
我们最简单的解释器开始,它只能识别以下三个指令,我们基于一点一点拓展实现我们的整个项目:
- LOAD_VALUE:加载值
- ADD_TWO_VALUES:相加
- PRINT_ANSWER:输出值
我们对7+5生成以下指令集:
1
2
3
4
5
6
7
8
9
| byte2exec = {
"inst": [
("LOAD_VALUE",0),
("LOAD_VALUE",1),
("ADD_TWO_VALUES",None),
("PRINT_ANSWER",None)
],
"num": [7,5]
}
|
之所以通过这种单指令和零指令的方式进行计算,是因为我们的Python解释器实际上是一个基于栈的虚拟机。
我们将指令和数据分开存放,这样保证了指令是定长的。因此,我们也需要向指令指出数据存放的位置,所以一个完整的指令集有两部分,指令和参数位置。对于不需要参数的零指令,我们用None表示。
现在我们可以基于栈来实现一个简单的解释器结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| class Interpreter:
def __init__(self):
self.stack = []
def LOAD_VALUES(self,number):
self.stack.append(number)
def ADD_TWO_VALUES(self):
first = self.stack.pop()
second = self.stack.pop()
total = first + second
self.stack.append(total)
def PRINT_ANSWER(self):
answer = self.stack.pop()
print(answer)
|
现在我们已经实现了一个虚拟机的基本结构和支持的指令,我们需要一个方法来驱动我们的虚拟机进行对指令的解析与执行:
1
2
3
4
5
6
7
8
9
10
11
12
| def run(self, code):
insts = code["inst"]
nums = code["num"]
for i in insts:
inst ,arg = i
if inst == "LOAD_VALUES":
num = nums[arg]
self.LOAD_VALUES(num)
elif inst == "ADD_TWO_VALUES":
self.ADD_TWO_VALUES()
elif inst == "PRINT_ANSWER":
self.PRINT_ANSWER()
|
现在我们可以尝试使用它们进行简单的计算3+4+5:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| code = {
"insts":[
("LOAD_VALUES",0),
("LOAD_VALUES",1),
("LOAD_VALUES",2),
("ADD_TWO_VALUES",None),
("ADD_TWO_VALUES",None),
("PRINT_ANSWER",None),
],
"nums":[3,4,5]
}
interpreter = Interpreter()
interpreter.run(code)
|
可以看到虚拟机按照预期输出了我们想要的结果。
变量
现在我们向虚拟机添加存储功能,我们可以将数值存入变量中,实现变量和值的映射关系,我们将实现以下两个指令:
- STORE_NAME:存入变量
- LOAD_NAME:取变量值
为了实现这个功能,我们需要再初始化一个内存空间(这里使用字典比较直观),用于存放变量名和值的绑定关系,同时需要在我们的code中添加变量名。我们的实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| class Interpreter:
def __init__(self):
self.stack = []
self.mem = {}
def LOAD_VALUE(self,number):
self.stack.append(number)
def ADD_TWO_VALUES(self):
x = self.stack.pop()
y = self.stack.pop()
self.stack.append(x+y)
def PRINT_ANSWER(self):
answer = self.stack.pop()
print(answer)
def STORE_NAME(self,name):
val = self.stack.pop()
self.mem[name] = val
def LOAD_NAME(self,name):
val = self.mem[name]
self.stack.append(val)
def parse_arg(self,inst,arg,code):
nums = ["LOAD_VALUE"]
vars = ["STORE_NAMES", "LOAD_NAMES"]
if inst in nums:
arg = code["nums"][arg]
elif inst in vars:
arg = code["vars"][arg]
return arg
def run(self, code):
insts = code["insts"]
for step in insts:
inst ,arg = step
arg = self.parse_arg(inst,arg,code)
if inst == "LOAD_VALUE":
self.LOAD_VALUE(arg)
elif inst == "STORE_NAME":
self.STORE_NAME(arg)
elif inst == "LOAD_NAME":
self.LOAD_NAME(arg)
elif inst == "ADD_TWO_VALUES":
self.ADD_TWO_VALUES()
elif inst == "PRINT_ANSWER":
self.PRINT_ANSWER()
|
这里我们可以试着运行一下x = 3; y = 7; print(x+y):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| code = {
"insts":[
("LOAD_VALUE",0),
("STORE_NAME",0),
("LOAD_VALUE",1),
("STORE_NAME",1),
("LOAD_NAME",0),
("LOAD_NAME",1),
("ADD_TWO_VALUES",None),
("PRINT_ANSWER",None),
],
"nums":[3,7],
"vars":["x","y"]
}
interpreter = Interpreter()
interpreter.run(code)
|
成功的运行了我们的函数。
程序结构优化
随着我们支持的指令增多,我们需要不断的通过if-else结构来进行对指令的执行。在我们的实现中,类的方法名和字节码中的指令是相同的,所以我们通过getattr方法来对run()进行优化:
1
2
3
4
5
6
7
8
9
10
| def execute(self, code):
insts = code["insts"]
for step in insts:
inst ,arg = step
arg = self.parse_arg(inst,arg,code)
inst = getattr(self,inst)
if arg is None:
inst()
else:
inst(arg)
|
Python字节码
现在我们可以尝试解析一下真实的Python字节码,我们可以以下面的这个函数为例:
1
2
3
4
5
6
| def cond():
x = 3
if(x < 5):
return 'yes'
else:
return 'no'
|
我们可以通过特殊方法__code__获取函数的字节码和元信息,具体的用法如下:
1
2
3
4
5
6
7
8
9
10
11
| 函数对象 (function)
│
└── __code__ (code对象 - 包含完整元数据)
│
├── co_code (字节码 - 仅指令)
├── co_consts (常量元组)
├── co_varnames (变量名元组)
├── co_names (全局名元组)
├── co_argcount (参数数量)
├── co_nlocals (局部变量数量)
└── ... 其他属性
|
这里我们可以通过这个方式得到我们的字节码指令
1
2
3
4
| codebyte = cond.__code__.co_code
codebyte = list(codebyte)
print(codebyte)
|
我们得到了这个函数的字节码,但是我们无法阅读它。所以我们需要用到Python中的字节码反汇编器dis,将字节码进行翻译并以可读的形式输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import dis
codebyte = cond.__code__.co_code
dis.dis(codebyte)
'''
0 RESUME 0
2 LOAD_CONST 1
4 STORE_FAST 0
6 LOAD_FAST 0
8 LOAD_CONST 2
10 COMPARE_OP 2 (<)
14 POP_JUMP_IF_FALSE 1 (to 18)
16 RETURN_CONST 3
>> 18 RETURN_CONST 4
'''
|
其中第一列是该指令对应的字节码索引,第二列是该字节码的可读形式,第三列是指令的参数索引(第4列可能会指出使用的是什么参数)
同时我们也可以使用dis库中的opname方法,将对应的字节码翻译成可读的指令:
1
2
3
4
5
6
7
8
| codebyte = cond.__code__.co_code
codebyte = list(codebyte)
print(dis.opname[codebyte[0]])
print(dis.opname[codebyte[4]])
'''
RESUME
STORE_FAST
'''
|
条件与循环
一个语言中条件分支和循环结构的能力也很重要,我们可以借这一段字节码深入的理解Python运行的实现。在我们的例子中if x>5被翻译成了:
1
2
3
4
| 6 LOAD_FAST 0
8 LOAD_CONST 2
10 COMPARE_OP 2 (<)
14 POP_JUMP_IF_FALSE 1 (to 18)
|
其中LOAD_FAST将局部变量加载到栈上,LOAD_CONST将常数5加载到栈上,然后通过COMPARE_OP指定的比较类型,对栈顶的两个数值进行比较,然后将比较结果放回栈上。最终POP_JUMP_IF_FALSE,根据比较的结果,跳转到指定的指令。跳转后要被加载的指令我们称之为跳转目标,作为POP_JUMP的参数,dis会用>>指出跳转目标。
有了条件判断和跳转之后,我们就可以实现最基本的循环结构,我们对下面这个循环结构进行分析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| def cond():
x = 1
while x<5:
x += 1
return x
'''
0 RESUME 0
2 LOAD_CONST 1
4 STORE_FAST 0
6 LOAD_FAST 0
8 LOAD_CONST 2
10 COMPARE_OP 2 (<)
14 POP_JUMP_IF_FALSE 11 (to 38)
>> 16 LOAD_FAST 0
18 LOAD_CONST 1
20 BINARY_OP 13 (+=)
24 STORE_FAST 0
26 LOAD_FAST 0
28 LOAD_CONST 2
30 COMPARE_OP 2 (<)
34 POP_JUMP_IF_FALSE 1 (to 38)
36 JUMP_BACKWARD 11 (to 16)
>> 38 LOAD_FAST 0
40 RETURN_VALUE
'''
|
要理解这个循环结构,我们需要从几个跳转指令入手。首先是第一个POP_JUMP,如果判断为真,就进入循环体结构,不为真就直接退出。第二个POP_JUMP则是判断是否退出循环结构。第三个比较特殊JUMP_BACKWARD,它将无条件跳转到循环体的起点。通过跳转和条件分支的功能,实现了循环结构。
其他的语法结构也是类似的,如if ... elif, for ,...,可以通过dis慢慢探索
栈帧
实现了数值的计算和控制转移之后,现在我们需要进一步认识Python
函数调用的过程。正如上面的那个例子,我们看到RETURN_VALUES,那么结束这个函数之后会返回到哪里呢?
如果我们在函数中,我们会返回到调用者。如果是在模块顶层,我们可能会直接结束程序。我们将上一层的信息返回给下一层,例如在递归调用时,我们还需要保存每一层的局部状态。这就引出了Frame的概念,frame是函数调用的一次执行的上下文。它在python运行的过程中不断的被创建和销毁。
对于一个code object,我们可能会有多个frame。但是对于一个frame,我们有且仅对应一个code object。
frame存在于调用栈之中(和C一样)。Python中有三种类型的栈结构:
- 调用栈:用来管理程序运行的函数调用状态
- 数据栈:用于存放数据
- 块栈:用于特定的控制流块,如异常和循环结构…
在调用栈的每个frame都有它自己的数据栈和块栈。以下面这个程序为例,它在调用栈中的状态大概就是这样的:
1
2
3
4
5
6
7
8
9
10
11
| >>> def bar(y):
... z = y + 3
... return z
...
>>> def foo():
... a = 1
... b = 2
... return a + bar(b)
...
>>> foo()
3
|
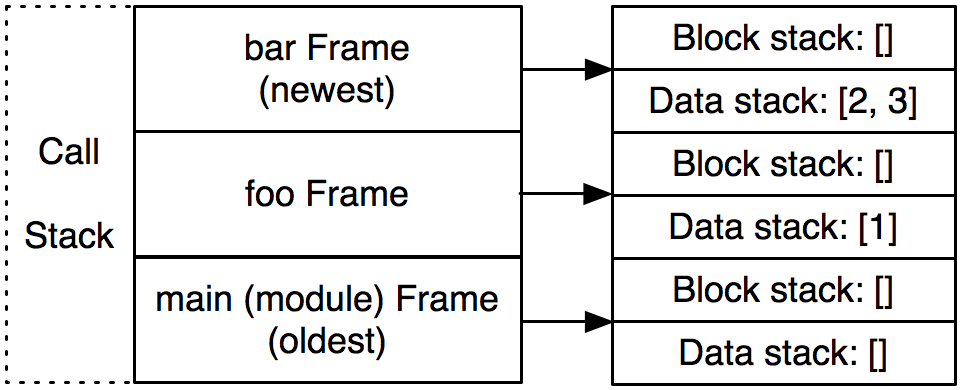 image.png
image.png
至此,我们对Python字节码的基本分析就结束了