我们已经学习了虚拟内存的作用和虚拟内存的基本使用过程,为了进一步的深入的理解虚拟内存的机制,我们需要要深入理解虚拟内存的基本原理。
地址翻译
现在我们将从底层除出发,理解硬件在虚拟内存中的角色。为了简化之后的说明,这里提前展示我们所要用到的符号以参考:
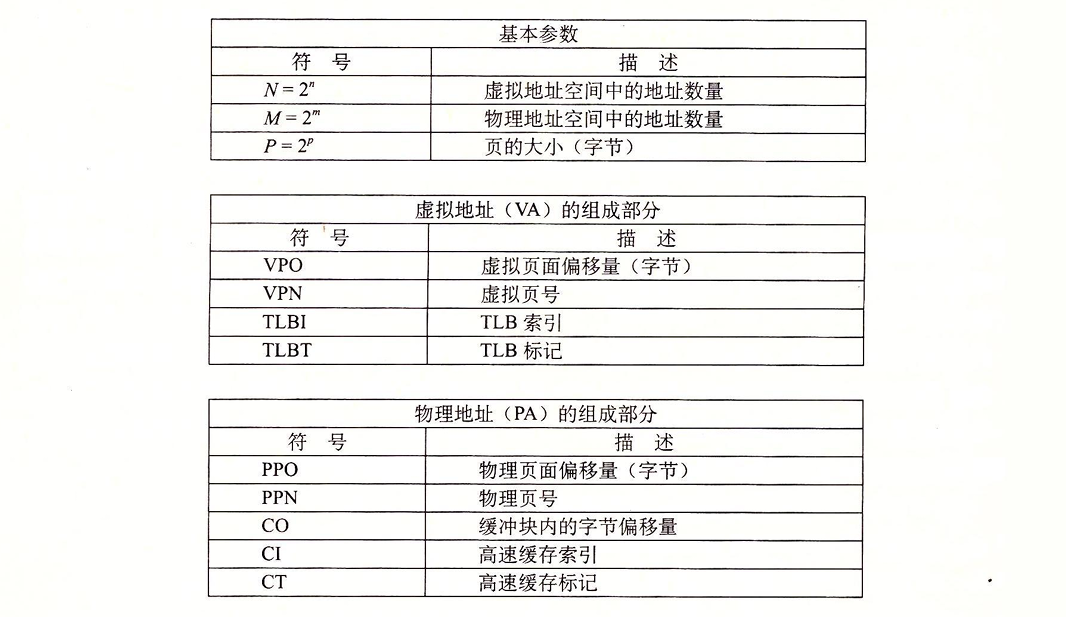
实际上,地址翻译就是一个N元素的虚拟地址空间(VAS)中的元素和一个M元素的物理地址空间(PAS)中元素的映射: $$ \begin{align*} MAP&:VAS \to PAS \cup \varnothing \\ MAP(A) &= \begin{cases} A' \text{ 如果虚拟地址A处的数据在PAS的物理地址A'处} \\ \varnothing \text{ 如果虚拟地址A处的数据不在物理内存中} \end{cases} \end{align*} $$ 下图演示了MMU如何利用页表来实现这种映射:
控制寄存器——页表基址寄存器(PTBR)指向当前页表。对于n位的虚拟地址,包含两个部分:
- 一个p位的虚拟页面偏移(VPO)
- 一个n-p位的虚拟页号(VPN),作为页表的索引
MMU通过VPN选择对应的PTE,同时PTE中的内容实际上就是物理页号(PPN),这样就可以通过虚拟页号访问到对应的物理页。至于偏移量,由于虚拟页和物理页的大小相同,所以虚拟页偏移量和物理页偏移量(PPO)是是相同的。
现在我们可以分析CPU硬件的执行步骤了:
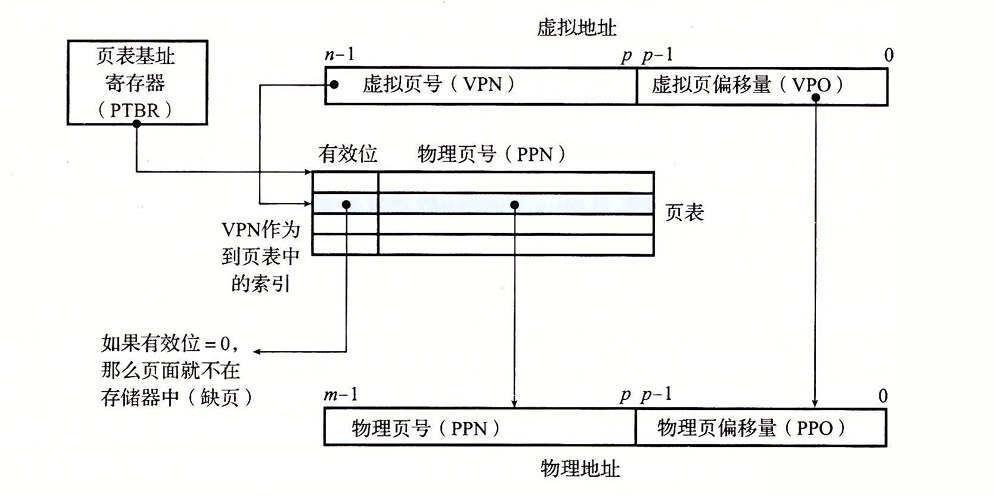
当页面命中时:
- 处理器生成一个虚拟地址VA并发送到MMU中
- MMU生成PTE地址(将VA拆分成VPN和VPO,VPN作为PTE地址),从内存中请求它
- 内存向MMU返回PTE
- MMU构造物理地址(返回的PTE就是PPN,物理地址=PPN+(PPO=VPO))发送给内存
- 内存通过物理地址找到数据字节返回给CPU
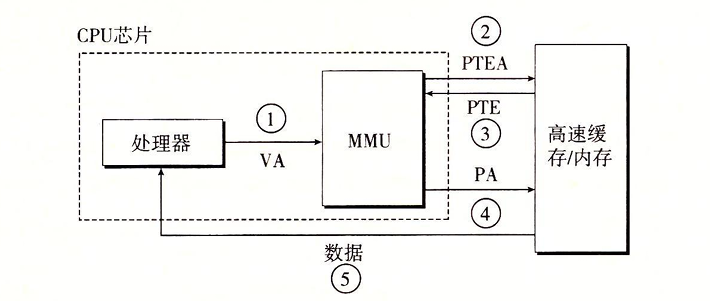
当缺页时:
- 前三步同上
- 返回的PTE有效位为0,MMU触发异常,CPU控制传递到内核中的缺页异常处理程序
- 缺页处理程序调入新的页面,并更新内存中的PTE
- 缺页处理程序返回原来的进程,再次执行导致缺页的指令。此时页面命中
结合高速缓存和虚拟内存
我们的系统一般既有虚拟内存的机制又有SRAM高速缓存,那么对于SRAM高速缓存,我们是应该使用物理地址访问还是虚拟地址访问呢?下图是一个将其结合起来的方案:
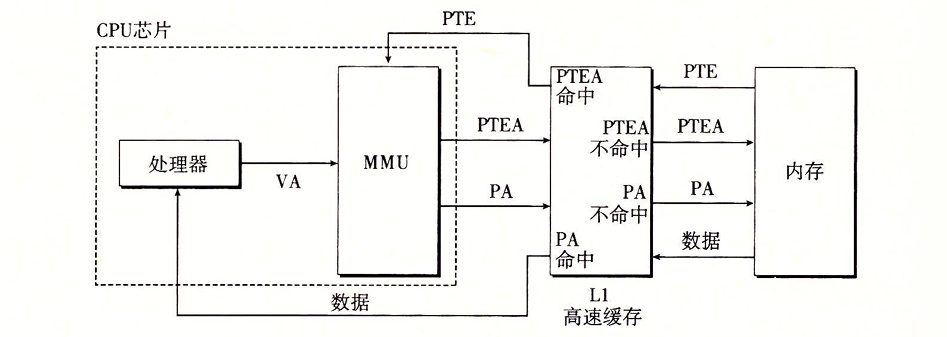
我们使用物理寻址的方案,先将VA转换为PTEA然后在L1中检索,如果命中就直接返回PTE,未命中则再取一次。拿到PTE后构造出PA再对L1进行检索,如果命中就返回PA,未命中就再取一次。L1的存在可以帮我们节省数据传送的时间。页表条目本质上也是数据字,所以也可以被缓存在L1中。
利用TLB加速地址翻译
CPU每次产生一个虚拟地址都需要查阅一个PTE,以便于将虚拟地址进行翻译。每次从内存取数据都需要花费几十到几百的周期,为了解决这个问题,我们引入了高速缓存,在命中的情况下,将开销降到了1到2周期。为了尽可能的减少开销,我们在MMU中引入了一个关于PTE的小缓存,即翻译后备缓冲器(TLB)
TLB是一个小的缓存,其每一行都保存有一个由单个PTE组成的块。其结构如下:

用于组选择和行匹配的索引和标记字段都是从VPN提取出来的。如果TLB有T=2^t个组,那么TLB索引(TLBI)是由VPN的t个最低位组成的,而TLB标记(TLBT)是由VPN中剩余的位组成的(用来行匹配)。
下图展示了TLB的工作过程:
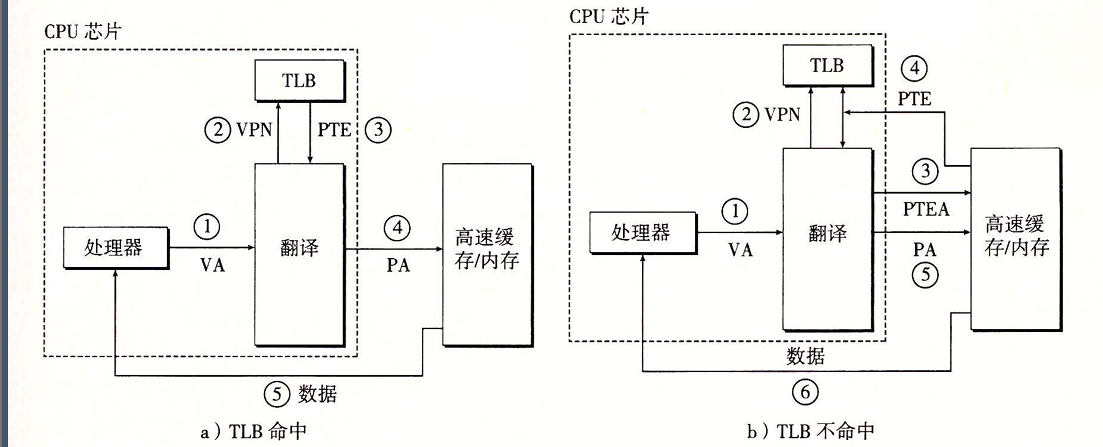
当TLB命中时:
- CPU产生VA
- MMU从TLB中取出相应的PTE
- MMU构造物理地址,发送到缓存
- 缓存返回数据字到CPU
当不命中时,MMU必须从L1中取出相应的PTE。新取出的PTE会覆盖TLB中的一个条目。
由于所有的地址翻译步骤都是在MMU中完成的,所以速度很快。
多级页表
到此为止,我们一直假设系统只使用一个单独的页表来进行地址翻译。如果我们有一个32位的地址空间、4KB的页面和一个4字节的PTE,那么即使我们只使用虚拟空间中很小的一部分,我们也需要一个4MB的页表驻留在内存中。对于64位的地址空间,这个问题更加明显,我们甚至需要4PB的页表常驻内存,这荒谬。为了解决这个问题,我们引入多级页表,用过层次结构来压缩。
我们以下图为例:
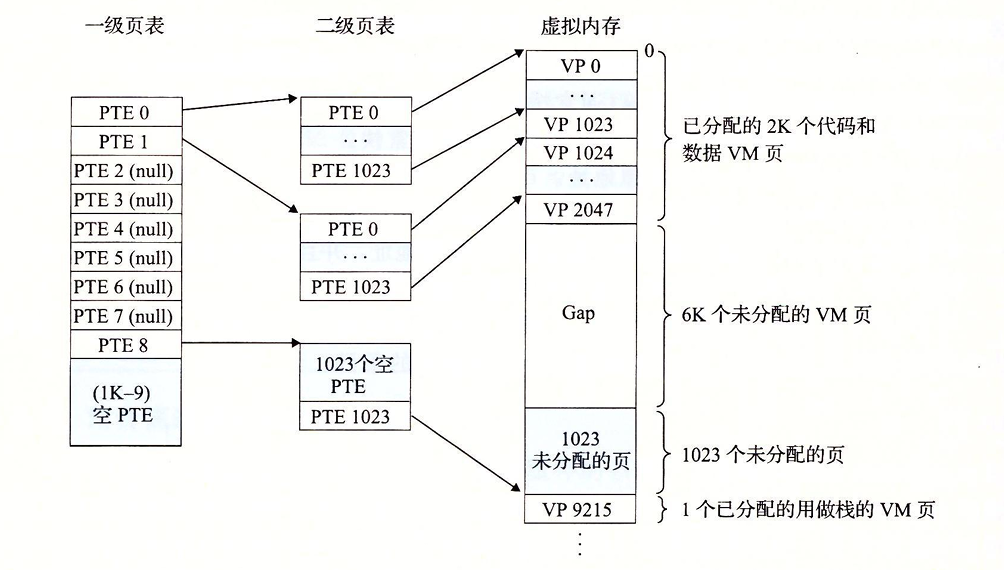
对于32位的地址空间,我们有4GB的地址空间,空间被分为4KB的页,每个页有一个4字节的页表条目。假设此时,虚拟空间有以下形式:内存的前2K个页面被分配给了代码和数据,接下来的6K个页面没有被分配,再接下里的1K个页面中有1023个未分配的页和一个分配作为栈的页面。
我们用一级页表中的每个PTE负责映射虚拟空间中一个4MB的片,这里的每一片都是由1024个连续的页面组成的。所以我们只需要1024个一级页表条目就可以指向4G大小的片。
如果片i中的每个页面都没有被分配,那么对应的一级页表条目i就是空的。反之,如果片i中至少有一个页是分配了的,那么一级PTEi就需要指向有一个二级页表的基址。每个二级页表的结构和一级页表都是一样的。
这种方法减少了内存的需求:
- 如果一级页表中的一个PTE是空的,那么对应的二级页表都不需要要存在,这样极大的节省了内存空间,因为虚拟地址空间大部分时候都是未分配的
- 只有一级页表才需要总是在主存中,VM系统在需要时创建、页面调入或调出二级表,进一步减少了主存的压力,只有常用的二级表才需要缓存在主存中
对于一个k级的页表层次结构的地址翻译。虚拟地址被分隔成k个VPN和一个VPO:
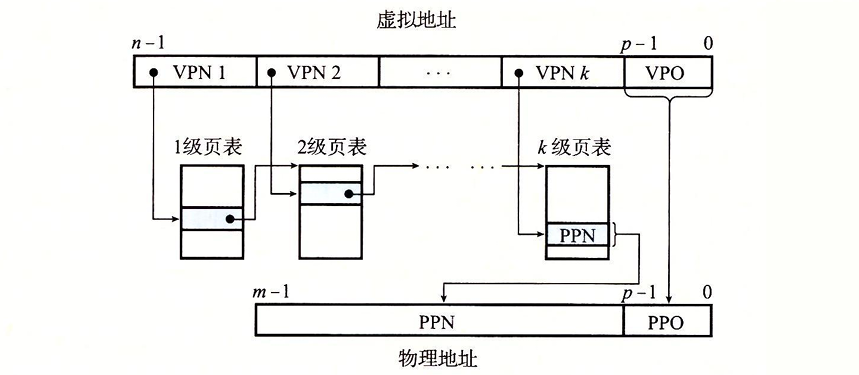
每个VPNi都是一个到第i个级页表的索引,第j级的每个页表中都指向第j+1级的某个页表的基址。第k级页表中的每个PTE包含某个物理页面的PPN,或一个磁盘块的地址。最终构造物理地址。
为了构造物理地址,MMU必须访问k个PTE。看上去开销很大,实际上TLB在这里会起到重要的作用,通过将不同层次上页表的PTE缓存起来,效率很不错。
端到端的地址翻译
讲了很多原理和过程,只有自己动手实践才是最真实的,我们用下面的的环境——在一个有TLB和L1 d-cache的系统上:
- 内存是按字节寻址的
- 内存访问是针对1字节的字
- 虚拟地址是14为长的(n=14)
- 物理地址是12位长的(m=12)
- 页面大小为64字节(P=64)
- TLB是四路组相联的,共有16个条目
- L1 d-cache是物理寻址、直接映射的,行大小4个字节16个组
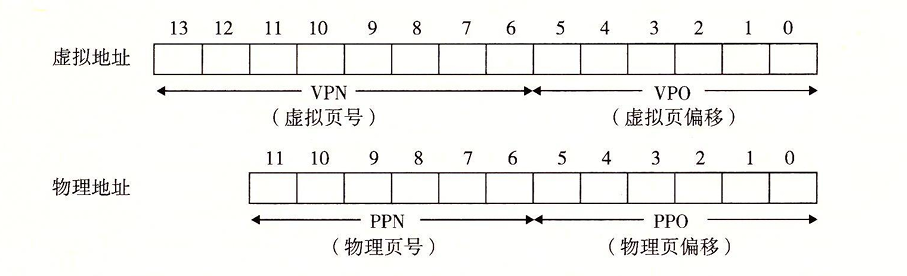
然后是对于TLB和高速缓存,访问这些设备时,我们通过以下方法对位进行划分:
- TLB 因为TLB有四个组,所以VPN的低2位用来做TLBI,高6位作为TLBT
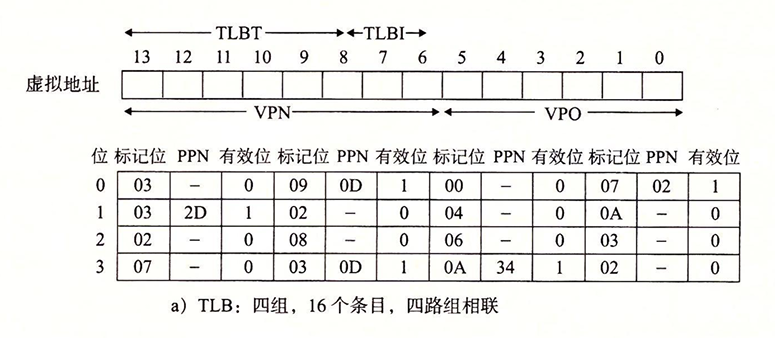
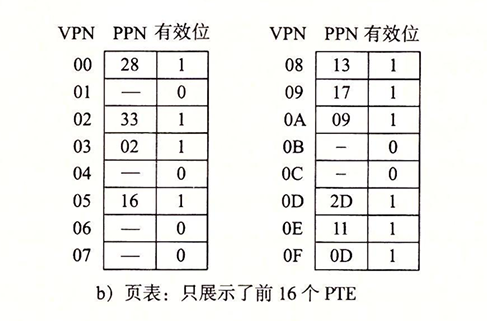
- 页表 这是一个单级设计,一共有256个页面,这里我们只关注前16个。为了方便,我们直接令VPN来标识PTE
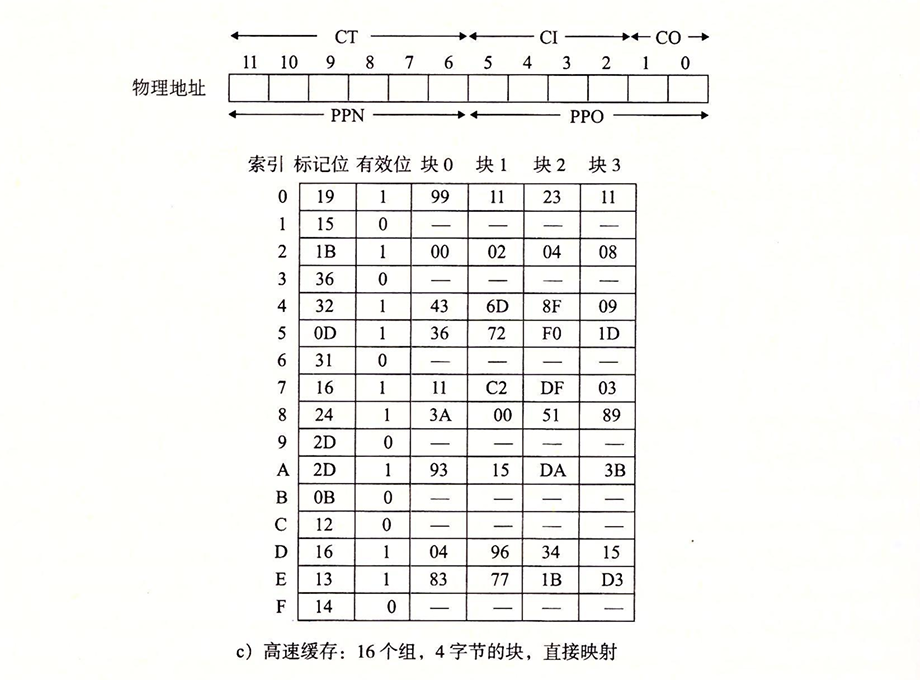
- 高速缓存 每个块都是4字节,所以用低2位作为块偏移(CO)。因为有16组,所以接下来的4位做组索引(CI)。剩下的6位做标记(CT)
现在,假设CPU执行一条读地址0x3d4处字节的加载指令会发生什么?
首先MMU会对VA进行解析,并在TLB中查找是否有缓存的PTE:
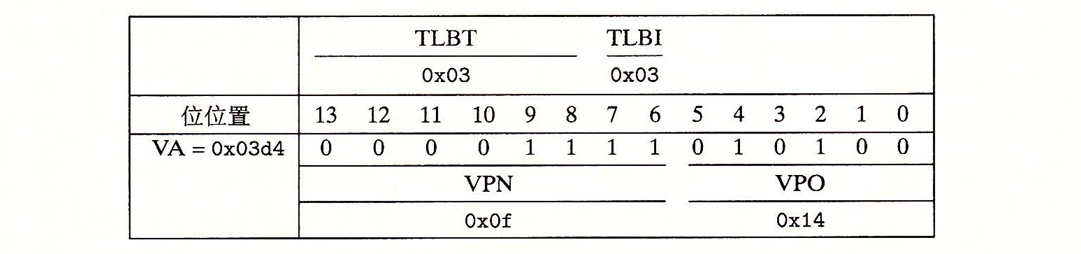
我们根据索引找到,获取了TLB中缓存的PPN0x0D,从而和VPO构造出物理地址0x0354。现在MMU将物理地址发送到缓存。我们对地址进行解析,查看L1是否缓存了我们需要的数据:
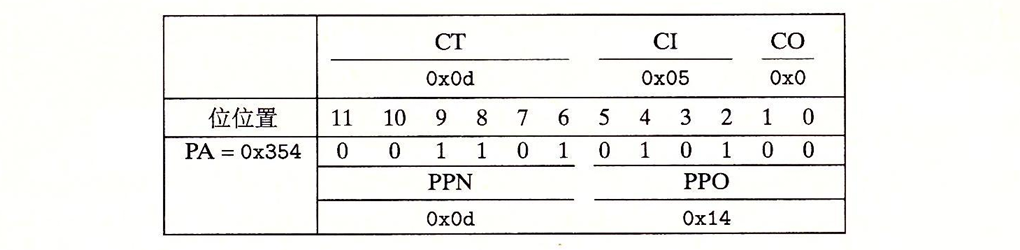
我们根据标记,行索引,块偏移,得到了数据0x36,并将其返回到MMU,随后MMU又将数据返回到CPU。至此,我们就完成了一次虚拟内存的使用。
当然以上的演示,都是理想状态下简化的情况。实际上我们可能会遇到不命中的问题。如果TLB不命中,那么MMU必须从页表PTE中取出PPN。如果得到的PTE是无效的,那么就产生缺页,那么就调用缺页异常处理程序;如果是有效的,但是缓存不命中。那么则又需要进行取用…