我们先前实现了卷积神经网络的各层,以及基本的前向传播,现在我们要进一步的完善整个神经网络,通过反向传播实现对权重的更新,从而提高神经网络的准确性。
反向传播
现在我们已经完成了神经网络的前向传播,现在我们需要对每个层进行反向传播以更新权重,来寻来你神经网络。进行反向传播,我们需要注意两点:
- 在前向传播的阶段,我们需要在每一层换从它需要用于反向传播的数据(如中间值等)。这也反映了,任意反向传播的阶段,都需要有着相应的前向阶段。
- 在反向传播阶段,每一层都会接受一个梯度,并返回一个梯度。其接受其输出($\frac{\partial L}{\partial out}$)的损失梯度,并返回其输入($\frac{\partial L}{\partial in}$)的损失梯度
我们的训练过程应该是这样的:
1 | # 前向传播 |
现在我们将逐步构建我们的反向传播函数:
Softmax层反向传播
我们的损失函数是: $$
\begin{align*}
L = -ln(p_c)
\end{align*}
$$
所以我们首先要计算的就是对于softmax层反向传播阶段的输入,其中out_s就是softmax层的输出。一个包含了10个概率的向量,我们只在乎正确类别的损失,所以我们的第一个梯度为:
$$
\begin{align*}
\frac{\partial L}{\partial out_s(i)} =
\begin{cases}
0 \space\space\space\space\space \text{ if i!=c} \\
-\frac{1}{p_i} \text{ if i=c}
\end{cases}
\end{align*}
$$ 所以我们正确的初始梯度应该是:
1 | gradient = np.zeros(10) |
然后我们对softmax层的前向传播阶段进行一个缓存:
1 | def forward(self, input): |
现在我们可以开始准备softmax层的反向传播了:
计算
我们已经计算出,损失对于激活函数值的梯度,我们现在需要进一步的推导,最终我们希望得到$\frac{\partial L}{\partial input} \frac{\partial L}{\partial w} \frac{\partial L}{\partial b}$
的梯度,以用于对权重的梯度训练。根据链式法则,我们应该有: $$
\begin{align*}
\frac{\partial L}{\partial w} &= \frac{\partial L}{\partial out} *
\frac{\partial out}{\partial t} * \frac{\partial t}{\partial w} \\
\frac{\partial L}{\partial b} &= \frac{\partial L}{\partial out} *
\frac{\partial out}{\partial t} * \frac{\partial t}{\partial b} \\
\frac{\partial L}{\partial input} &= \frac{\partial L}{\partial out}
*
\frac{\partial out}{\partial t} * \frac{\partial t}{\partial input}
\end{align*}
$$ 其中
t = w * input + b,out则是softmax函数的输出值,我们可以依次求出。对于$\frac{\partial L}{\partial out}$我们有:
$$
\begin{align*}
out_s(c) &= \frac{e^{t_c}}{\sum_{i}e^{t_i}} = \frac{e^{t_c}}{S} \\
S &= \sum_{i}e^{t_i} \\
\to out_s(c) &= e^{t_c}S^{-1}
\end{align*}
$$ 现在我们求$\frac{\partial
out_s(c)}{\partial
t_k}$,需要分别考虑k=c和k!=c的情况,我们依次进行求导:
$$
\begin{align*}
\frac{\partial out_s(c)}{\partial t_k} &= \frac{\partial
out_s(c)}{\partial S}
*\frac{\partial S}{\partial t_k} \\
&= -e^{t_c}S^{-2}\frac{\partial S}{\partial t_k} \\
&= -e^{t_c}S^{-2}(e^{t_k}) \\
&= \frac{-e^{t_c}e^{t_k}}{S^2} \\
\\
\frac{\partial out_s(c)}{\partial t_c} &=
\frac{Se^{t_c}-e^{t_c}\frac{\partial S}{\partial t_c}}{S^2} \\
&= \frac{Se^{t_c}-e^{t_c}e^{t_c}}{S^2} \\
&= \frac{e^{t_c}(S-e^{t_c})}{S^2} \\
\to
\frac{\partial out_s(k)}{\partial t} &=
\begin{cases}
\frac{-e^{t_c}e^{t_k}}{S^2} \space\space\space\space \text{ if k!=c} \\
\frac{e^{t_c}(S-e^{t_c})}{S^2} \text{ if k=c}
\end{cases}
\end{align*}
$$ 最后我们根据公式t = w * input + b得到: $$
\begin{align*}
\frac{\partial t}{\partial w}&=input \\
\frac{\partial t}{\partial b}&=1 \\
\frac{\partial t}{\partial input}&=w
\end{align*}
$$ 现在我们可以用代码实现这个过程了
实现
1 | def backprop(self,d_L_d_out): |
由于softmax层的输入是一个输入体积,在一开始被我们展平处理了,但是我们返回的梯度也应该是一个同样大小的输入体积,所以我们需要通过reshape确保这层的返回的梯度和原始的输入格式相同。
我们可以测试一下softmax反向传播后的训练效果:
1 | import numpy as np |
可以看到准确率有明显的提升,说明我们softmax层的反向传播在很好的进行
1 | Start! |
池化层传播
在前向传播的过程中,最大池化层接收一个输入体积,然后通过2x2区域的最大池化,将宽度和高度都减半。而在反向传播中,执行相反的操作:我们将损失梯度的宽度和高度都翻倍,通过将每个梯度值分配到对应的2x2区域的最大值位置:
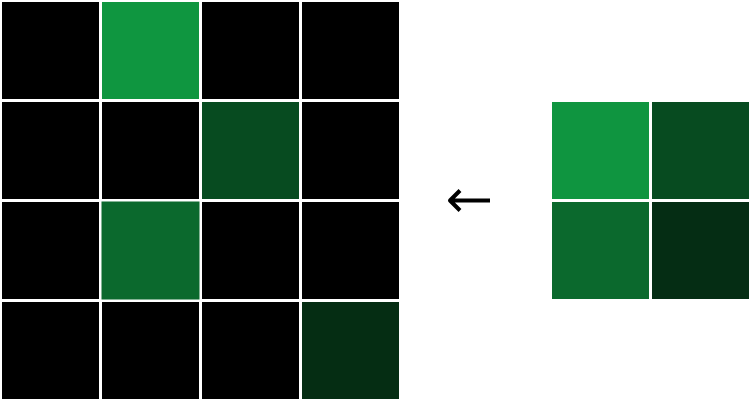
每个梯度都被分配到原始最大值的位置,然后将其他梯度设置为0.
为什么是这这样的呢?在一个2x2区域中,由于我们只关注区域内的最大值,所以对于其他的非最大值,我们可以几乎忽略不计,因为它的改变对我们的输出结果没有影响,所以对于非最大像素,我们有$\frac{\partial L}{\partial inputs}=0$。另一方面来看,最大像素的$\frac{\partial output}{\partial input}=1$,这意味着$\frac{\partial L}{\partial output}=\frac{\partial L}{\partial input}$
所以对于这一层的反向传播,我们只需要简单的还原,并且填充梯度值到最大像素区域就行了
实现
1 | def backprop(self,d_L_d_out): |
这一部分并没有什么权重用来训练,所以只是一个简单的数据还原。
卷积层反向传播
卷积层的反向传播,我们需要的是卷积层中的滤波器的损失梯度,因为我们需要利用损失梯度来更新我们滤波器的权重,我们现在已经有了$\frac{\partial L}{\partial output}$,我们现在只需要计算$\frac{\partial output}{\partial filters}$,所以我们需要知道,改变一个滤波器的权重会怎么影响到卷积层的输出?
实际上修改滤波器的任意权重都可能会导致滤波器输出的整个图像,下面便是很好的示例:
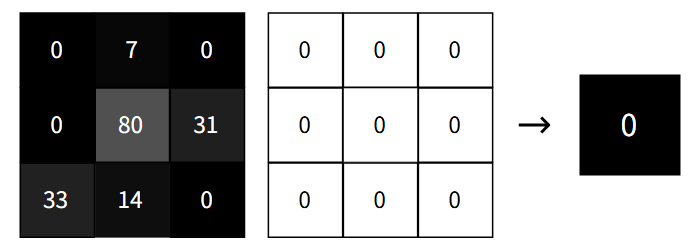
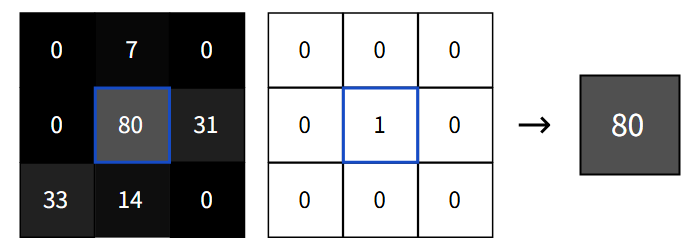
同样的对任何滤波器权重+1都会使输出增加相应图像像素的值,所以输出像素相对于特定滤波器权重的导数应该就是相应的图像元素。我们可以通过数学计算来论证这一点
计算
$$ \begin{align*} out(i,j) &= convolve(image,filiter) \\ &= \sum_{x=0}^3{}\sum_{y=0}^{3}image(i+x,j+y)*filiter(x,y) \\ \to \frac{\partial out(i,j)}{\partial filiter(x,y)} &=image(i+x,i+y) \end{align*} $$
我们将输出的损失梯度引进来,我们就可以获得特定滤波器权重的损失梯度了: $$ \begin{align*} \frac{\partial L}{\partial filiter(x,y)} = \sum_{i}\sum_{j}\frac{\partial L}{\partial out(i,j)} * \frac{\partial out(i,j)}{\partial filter(x,y)} \end{align*} $$ 现在我们可以实现我们卷积层的反向传播了:
实现
1 | def backprop(self, d_L_d_out): |
现在我们可以对我们的神经网络进行一个完整的训练了,我们可以看到训练的结果如下:
效果还是非常不错的。
完善
和之前的网络不同,CNN的训练集比较庞大,如果每次启动都要训练遍参数就太麻烦了,所以我们可以再每次训练之后将参数保存下来。下次再要使用就可以直接加载而不用重复训练。所以我们可以编写保存模型:
1 | import pickle |
如果我们想要自己尝试手写输入,来测试模型的效果,我们可能希望有个手写板,所以我们可以再写一个手写板的类:
1 | class DrawingBoard: |
现在我们就可以使用它了,我们先进行训练,然后用保存的参数,来进行手写数字识别,我把整个网络的源代码放在下面:
1 | import numpy as np |