上一篇文章中我们学习了循环神经网络,我们现在已经基本理解了神经网络怎么去处理数据/序列。可是对于图片、音频、文件之类的数据,我们该怎么去处理呢?相较于数据、序列,对图片使用传统神经网络会导致更大的开销。其他的数据类型也是同理,所以接下来我们将要认识卷积神经网络。
卷积神经网络简介
卷积神经网络的一个经典应用场景是对图像进行分类,可是我们可不可以使用普通的神经网络来实现呢?可以,但是没必要。对于图像数据处理,我们需要面临两个问题:
- 图像数据很大
假如我们要处理的图像大小是100x100甚至更大。那么构建一个处理100x100的彩色图像的神经网络,我们需要
100x100x3 = 30000个输入特征。我们用一个1024个节点的中间层,意味着我们在一层中就要训练30000x1024 = 30720000个权重。这样会导致我们的神经网络十分庞大
- 图像特征的位置会改变
同一个特征可能是在图像中的不同位置,你可能可以训练出一个对于特定图像表现良好的网络。但是当你对图像进行一定的偏移,可能就会导致结果发生错误的改变
使用传统的神经网络来解决图像问题,无异于是浪费的。它忽视了图像中任意像素与其邻近像素的上下文关系,图像中的物体是由小范围的局部特征组成的,对每个像素都进行分析,是毫无意义的。
所以我们需要使用卷积神经网络来解决这些问题。
目标
这一次我们的目标是实现一个手写数字识别的卷积神经网络,用到的是MNIST的手写数字数据集。也就是给定一个图像,将其分类为一个数字。
 image.png
image.png
MNIST数据集中的每张图片都是28*28的大小,包含一个居中的灰度数字。我们将根据这个数据集来对神经网络进行训练。
卷积
我们首先要理解卷积神经网络中的卷积是什么意思。卷积实际上是一种加权平均的操作。它的相当于一个滤波器,能够提取原始数据中的某种特定特征。我们往往使用卷积核来进行这个操作。
而神经网络中的卷积层则是根据过滤器实现对局部特征的处理,我们以下面这个操作为例:
对于一个垂直特征的卷积核,我们可以计算出这里的特征值
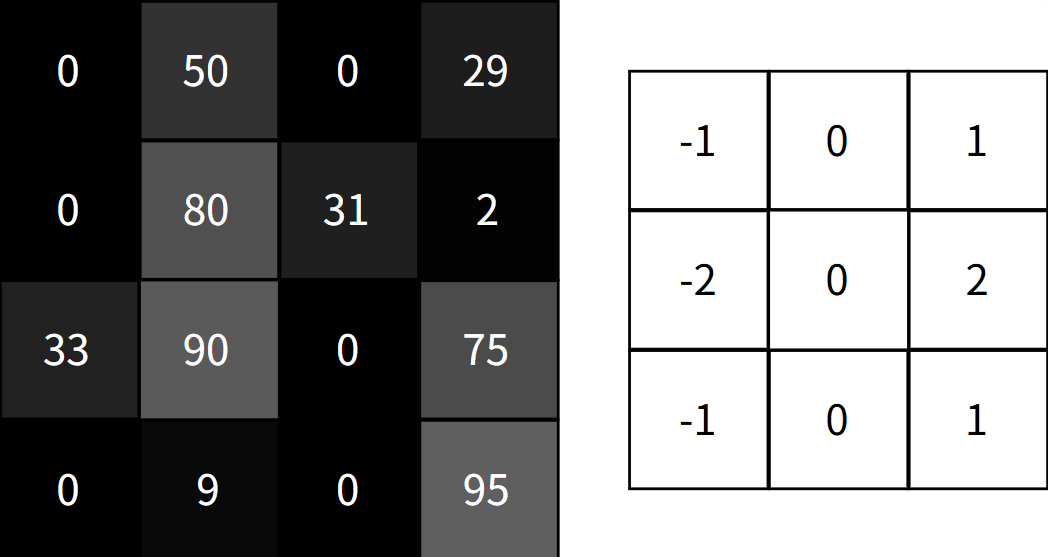 image.png
image.png
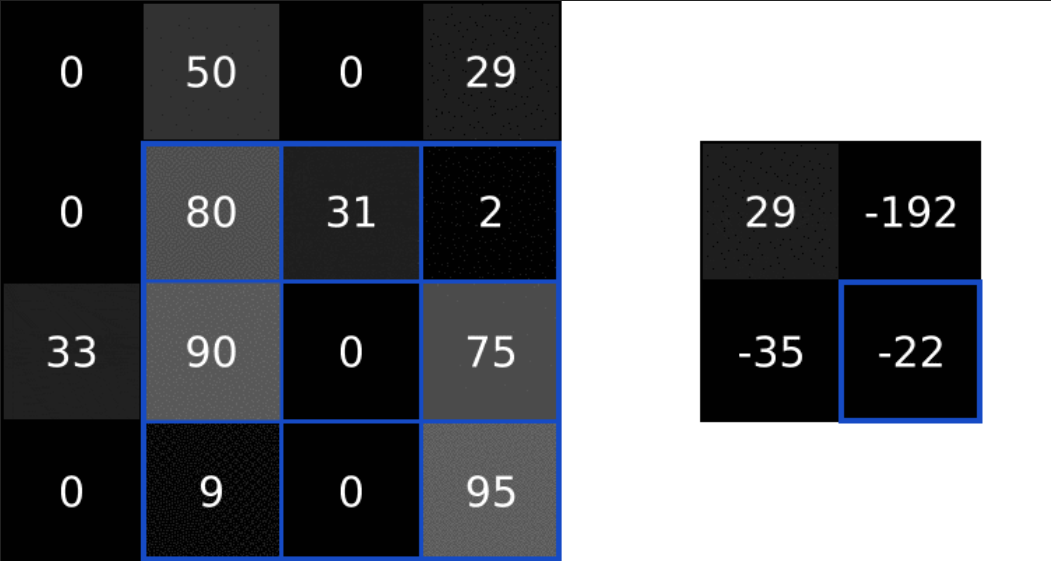 image.png
image.png
我们们可以通过对图像中的数据进行卷积操作从而实现对局部特征的提取。这就和我们将要用到的卷积核有关了。
卷积核
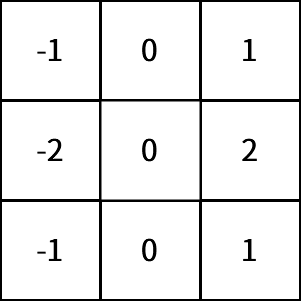 image.png
image.png
这是一个垂直sobel滤波器,通过它对图像进行卷积操作,我们可以提取出图像的垂直特征:
 image.png
image.png
同样的,我们有对应的水平SObel卷积核,可以提取出图像的水平特征:
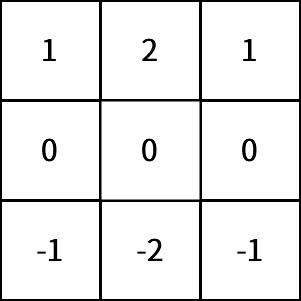 image.png
image.png
 image.png
image.png
而Sobel滤波器,我们可以理解成边缘检测器。通过提取手写数字边缘的特征,有利于网络在后续更好的进行图像识别。
填充
对于卷积这一步,我们对一个4x4的输入图像使用一个3x3的滤波器,我们会得到一个2x2的输出图像。如果我们希望输出图像和输入图像保持相同的大小。我们则需要向周围添加0,使得滤波器可以在更多的位置上覆盖
 image.png
image.png
这种操作,我们称之为相同填充。如果不适用任何填充,我们称之为有效填充。
卷积层的使用
我们现在知道卷积层通过使用一组滤波器将输入图像转换为输出图像的卷积层了。我们将使用一个具有8个滤波器的小卷积层作为我们网络中的起始层,意味着,它将28x28的输入图像转换为26x26x8的输出体积:
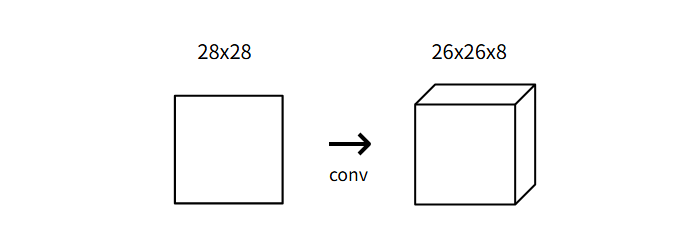 image.png
image.png
每个卷积层的8个过滤器产生一个26x26的输出,这是因为我们用到的是3x3的卷积核作为我们的滤波器,所以我们需要训练的权重有3x3x8 = 72个权重
实现
现在我们尝试用代码实现一个卷积层:
1
2
3
4
5
6
7
8
| import numpy as np
class Conv3x3:
def __init__(self,num_filters):
self.num_filters = num_filters
self.filters = np.random.randn(num_filters,3,3) / 9
|
我们注意到我们对生成的卷积核中做了一个权重初始化的工作,这是因为:
- 如果初始权重太大,那么输入数据经过卷积计算之后会变得很大,在反向传播的过程中梯度值也会变得很大,从而导致参数无法收敛,即梯度爆炸
- 如果初始权重太小,由于激活函数的作用,输入的数据会层层缩小,导致反向传播过程中的梯度值变得绩效。难以实现对权重的有效更新,我们称之为梯度消失
这里我们用到Xavier初始化来解决这个问题,他指出,在保持网络层在初始化时,其输入核和输出的方差应该尽可能的相同。这样信号就可以在网络中稳定的传播。
我们设输入为y输出为x,权重矩阵为W。则有: $$
\begin{align*}
Var(W) = \frac{1}{n_{in}}
\end{align*}
$$
其中n_in是输入的节点数量,这里就是3x3,所以初始化时需要/9
接下来是实际的卷积部分的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| class Conv3x3:
def __init__(self,num_filters):
self.num_filters = num_filters
self.filters = np.random.randn(num_filters,3,3) / 9
def iterate_regions(self,image):
h,w = image.shape
for i in range(h-2):
for j in range(w-2):
im_region = image[i:(i+3),j:(j+3)]
yield im_region,i,j
def forward(self,input):
h,w = input.shape
output = np.zeros((h-2,w-2,self.num_filters))
for im_region,i,j in self.iterate_regions(input):
output[i,j] = np.sum(im_region * self.filters,axis=(1,2))
return output
|
这里我们很多用法涉及到numpy的一些高级使用,可以在这里参考NumPy现在我们可以检查我们的卷积层是否输出了我们理想的结果:
1
2
3
4
5
6
7
8
| from conv import Conv3x3
import tensorflow as tf
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
conv = Conv3x3(8)
output = conv.forward(x_train[0])
print(output.shape)
|
池化
图像中的相邻元素往往是相似的,所以卷积层输出中,通常相邻元素产生相似的值。结果导致卷积层输出中包含了大量的冗余信息。为了解决这个问题我们需要对数据进行池化
它所做的事情很简单,往往是将输出中的值聚合称为更小的尺寸。池化往往是通过简单的操作,如max,min,average实现的。比如下面就是一个池化大小为2的最大池化操作
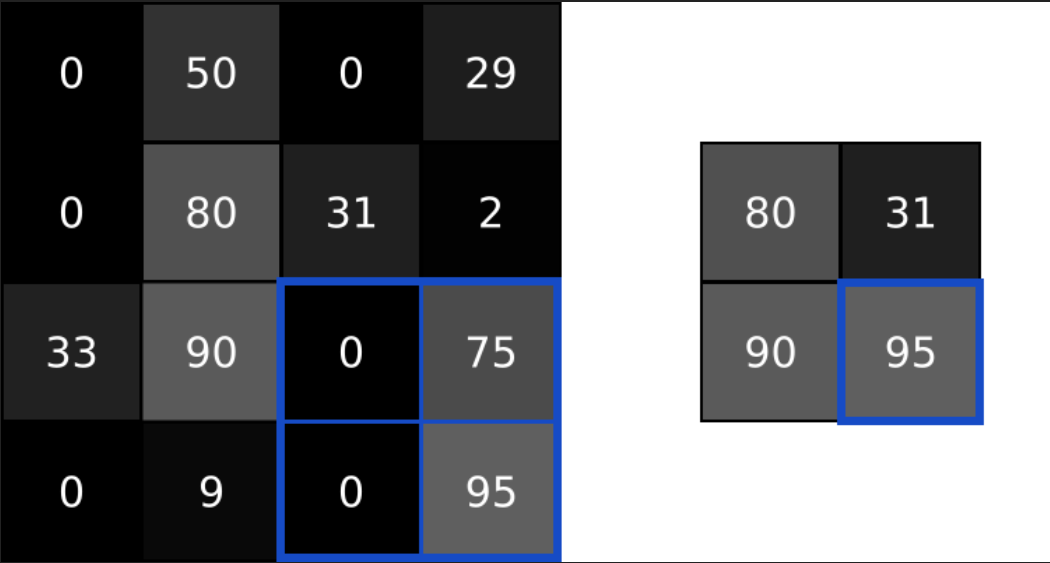 image.png
image.png
池化将输入的宽度和高度除以池化大小。在我们的卷积神经网络中,我们将在初始卷积层之后放置一个池化大小为2的最大池化层,池化层将26x26x8的输入转化为13x13x8的输出:
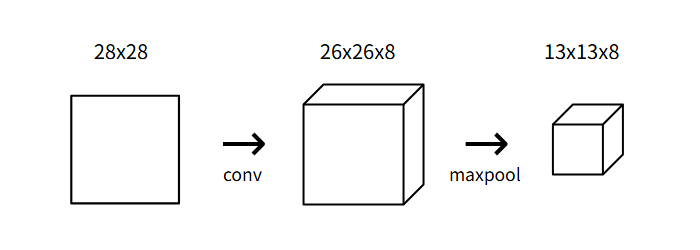 image.png
image.png
实现
我们现在用代码实现和conv类相似的MaxPool2类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| import numpy as np
class MaxPool2:
def iterate_regions(self,image):
h,w,_ = image.shape
new_h = h // 2
new_w = w // 2
for i in range(new_h):
for j in range(new_w):
im_region = image[i*2:(i+1)*2,j*2:(j+1)*2]
yield im_region,i,j
def forward(self,input):
h,w,num_filters = input.shape
output = np.zeros((h//2,w//2,num_filters))
for im_region,i,j in self.iterate_regions(input):
output[i,j] = np.amax(im_region,axis=(0,1))
return output
|
这个类和之前实现的Conv3x3类类似,关键在于从一个给定的图像区域中找到最大值,我们使用数组的最大值方法np.amax()来实现。我们来测试一下池化层:
1
2
3
4
5
6
7
8
9
10
11
12
| from conv import Conv3x3
from maxpool import MaxPool2
import tensorflow as tf
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
conv = Conv3x3(8)
pool = MaxPool2()
output = conv.forward(x_train[0])
output = pool.forward(output)
print(output.shape)
|
Softmax层
现在我们通过前两层,已经提取出了数字特征,现在我们希望能够赋予其实际预测的能力。对于多分类问题,我们通常使用Softmax层作为最终层——这是一个使用Softmax函数作为激活函数的全连接层(全连接层就是每个节点都与前一层的每个输入相联)
我们将使用一个包含10个节点的Softmax层作为CNN的最后一层,每个节点代表一个数字。层中的每个节点都连接到之前的输出中。在Softmax变化之后,概率最高的数字就是我们的输出。
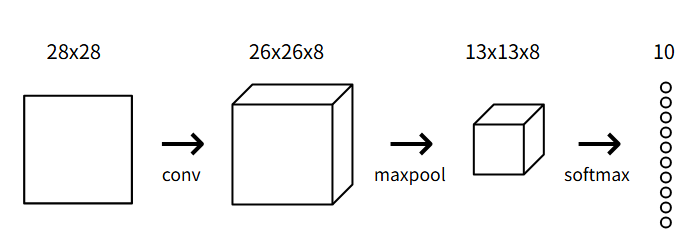 image.png
image.png
交叉熵损失
我们现在既然可以输出最终的预测结果了,它输出的结果是一个概率,用来量化神经网络的对其预测的信心。同样的,我们也需要一种方法来量化每次预测的损失。这里我们使用交叉熵损失来解决这个问题:
$$
\begin{align*}
L = -ln(p_c)
\end{align*}
$$ 其中c指的是正确的类别,即正确的数字。而pc代表类别c的预测概率。我们希望损失越低越好,对网络的损失进行量化,有利于后续的神经网络训练。
实现
我们同上步骤,实现一个Softmax层类:
1
2
3
4
5
6
7
8
9
10
11
12
13
| import numpy as np
class Softmax:
def __init__(self, input_len, nodes):
self.weights = np.random.randn(input_len,nodes) / nodes
self.biases = np.zeros(nodes)
def forward(self, input):
input = input.flatten()
totals = np.dot(input,self.weights) + self.biases
exp = np.exp(totals)
return exp/np.sum(exp,axis=0)
|
现在,我们已经完成了CNN的整个前向传播,我们可以简单的测试一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| import numpy as np
from conv import Conv3x3
from maxpool import MaxPool2
from softmax import Softmax
import tensorflow as tf
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
test_images = x_test[:1000]
test_labels = y_test[:1000]
conv = Conv3x3(8)
pool = MaxPool2()
softmax = Softmax(13*13*8,10)
def forward(image,label):
out = conv.forward((image / 255) - 0.5)
out = pool.forward(out)
out = softmax.forward(out)
loss = -np.log(out[label])
acc = 1 if np.argmax(out) == label else 0
return out,loss,acc
print("Start!")
loss = 0
num_correct = 0
for i,(im,label) in enumerate(zip(test_images,test_labels)):
_, l, acc = forward(im,label)
loss += l
num_correct += acc
if i%100 == 99:
print(
'[Step %d] Past 100 steps :Average Loss %.3f | Accuracy %d%%' %
(i+1,loss/100,num_correct)
)
loss = 0
num_correct = 0
|
我们可以得到下面的输出:
1
2
3
4
5
6
7
8
9
10
11
| Start!
[Step 100] Past 100 steps :Average Loss 2.566 | Accuracy 13%
[Step 200] Past 100 steps :Average Loss 2.447 | Accuracy 13%
[Step 300] Past 100 steps :Average Loss 2.500 | Accuracy 13%
[Step 400] Past 100 steps :Average Loss 2.520 | Accuracy 10%
[Step 500] Past 100 steps :Average Loss 2.431 | Accuracy 9%
[Step 600] Past 100 steps :Average Loss 2.477 | Accuracy 6%
[Step 700] Past 100 steps :Average Loss 2.491 | Accuracy 11%
[Step 800] Past 100 steps :Average Loss 2.598 | Accuracy 7%
[Step 900] Past 100 steps :Average Loss 2.545 | Accuracy 7%
[Step 1000] Past 100 steps :Average Loss 2.610 | Accuracy 10%
|
这是因为我们对权重进行了随机初始化,所以现在神经网络的表现更像是随机猜测,所以准确率趋近于10%