在上一章中的加载过程中,我们大致了解了动态链接的过程,接下来我们要进一步认知其背后的原理。
位置无关代码
共享库的主要目的就是让多个正在运行的进程共享内存中相同的库代码,从而节约内存空间。可是多个进程是怎么共享同样一个副本的呢?
给每个共享库分配有一个事先预备的专用的地址空间,然后有要求加载器总是在这个地址加载共享库。这样虽然很简单,但是对内存空间的使用效率差。即使进程不适用这个库,这部分空间也会被分配出来。而且难以管理,每当我们又有一个新的库们就需要重新分配一篇空间。久而久之,这会导致地址空间分裂成各种各样的内存碎片
为了避免这个问题,现代操作系统令共享模块的代码段可以加载到内存的任何位置,而无需链接器修改。这样就可以实现无限多个进程共享一个共享模块的代码段的单一副本。这种可以加载而无需重定位的代码称为位置无关代码(PIC)。可以通过-fpic选项指示GNU编译系统生成PIC代码。
对于在前面已经链接好了的目标模块,我们并不需要特殊的处理,因为他们的相对位置已经固定。我们可以用PC相对寻址来编译这些引用。然而对于共享模块定义的外部过程和全局变量的引用,我们需要进行处理:
PIC数据引用
下面我们要用到的方法是基于一个事实的,链接阶段之后,程序的代码段和数据段的距离(代码段首->数据段首)总是不变的。所以我们说代码段中任何指令和数据段中任何变量间的距离都是一个运行时的常量。与绝对内存的位置是无关的。
因此我们可以利用这个事实,在数据段的开始位置创建一个GOT表(全局偏移量表)。每个被目标模块引用的全局数据目标(过程或全局变量)都有一个8字节条目。编译器会为每个条目创建一个重定位记录。在加载时,动态链接器会将GOT中的每个条目包含其目标正确的绝对地址以供跳转。每个全局目标的目标模块都有自己的GOT。
我们以下图为例:
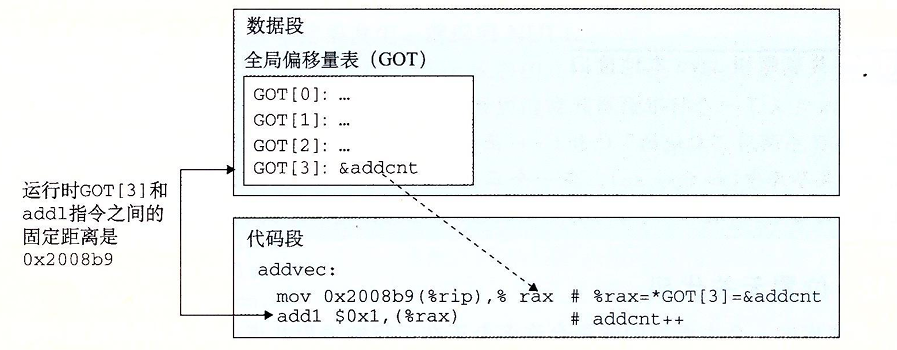
我们想要知道addcnt的地址,我们实际上只需要知道PC指向的地址和GOT表的起始位置,以及指定全局目标在GOT表中的索引,然后我们可以计算出固定距离 = (GOT基址-下一条指令的地址)+ GOT索引*8。之后我们就可以实现位置无关的数据引用了。
PIC函数调用
假设一个程序调用一个共享库定义的函数。编译器不知道这个函数的运行时地址,因为共享模块可能会被加载到任意内存位置。理想的方法时为它创建一个重定位记录,然后再动态链接器加载时解析它,可这也意味着在链接之后运行前,调用模块的代码段会被修改,可是我们又需要确保代码段只是可读的。因此我们使用延迟绑定技术+位置无关
使用延迟绑定技术,我们将函数调用的加载延迟到被调用的地方,这样可以避免长时间的加载过程。同时只有第一次过程调用的运行时开销比较大,之后的每次的调用只需要支付一次跳转指令和一个间接的地址引用。
通过延迟绑定实现函数调用的位置无关,是通过两个数据结构实现的:GOT 和 PLT(过程链接表)。如果一个目标模块调用定义在共享库中的任何函数,那么它都会生成自己的GOT和PLT。GOT是数据段的一部分。PLT是代码段的一部分。我们可以详细了解下他们的作用:
过程链接表(PLT)
PLT是一个数组,其中每个条目都是一个十六字节的代码。PLT[0]是一个特殊条目,它跳转到动态链接器延迟绑定函数的入口,来修改GOT表指定符号的内容。每个被调用的库函数都有自己的PLT条目,每个条目负责调用一个具体的函数。PLT[1]调用系统启动函数(
__libc_start_main),它初始化执行环境,调用main函数并返回值。从PLT[2]开始条目调用用户代码调用的函数。全局偏移量表(GOT)
GOT是一个数组,每个条目都是8字节地址。和PLT联合使用时,GOT[0]和GOT[1]包含动态链接器在解析函数地址时需要的信息。GOT[2]是动态链接器ld-linux.so的模块的入口。其余每个每个条目对应一个被调用的函数,其地址在运行时被解析。每个条目都有一个相匹配的PLT条目。且初始时每个GOT条目都指向指定PLT条目的第二条指令。
下面我们将会演示一个延迟绑定的过程:
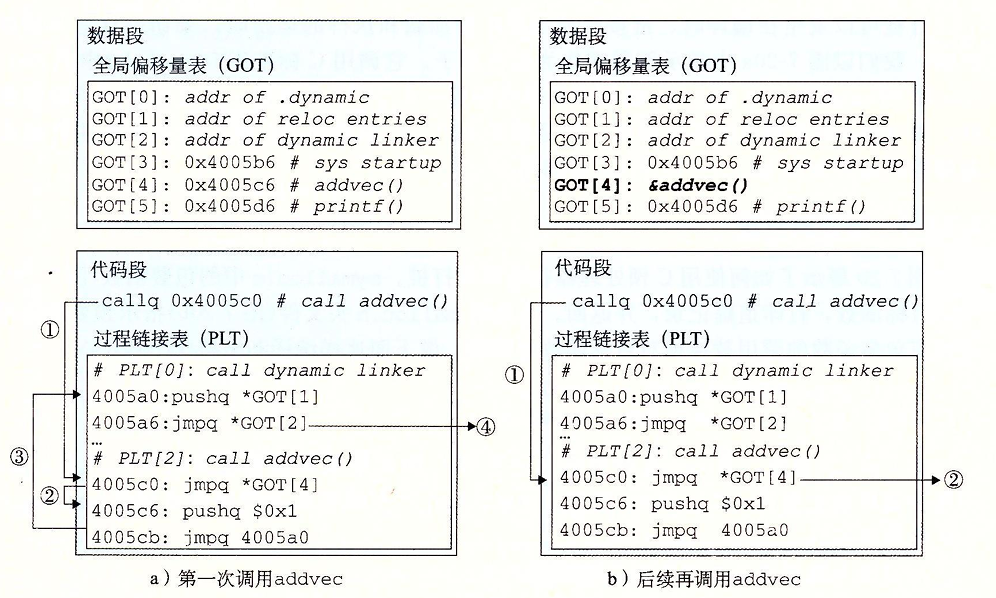
对于第一次调用:
- 我们会直接程序调用到addvec的PLT条目PLT[2]
- 第一条PLT指令通过间接跳转将控制传递到了第二条PLT指令(因为GOT表初始指向第二条指令)
- 然后将符号addvec的ID(0x1)压入栈中,将控制转移到PLT[0]中
- PLT[0]将存储在GOT[1]中的动态链接信息也压入栈中,然后将控制转移到动态链接器的入口。动态链接器将根据动态链接的符号信息和调用函数的符号ID来确定此时调用函数的绝对内存地址。并重写GOT[4]的存储地址,并将控制转移到addvec
后续调用:
- 控制传递到PLT[2]
- 不过这一次通过GOT[4]的间接跳转回将控制直接转移到addvec
库打桩机制
LInux链接器支持库打桩,它允许你截获对共享库的调用,取而代之执行自己的代码。使用过打桩机制,我们就可以追踪库函数的调用次数,验证和追踪它的输入和输出值,甚至将它替换为一个完全不同的实现。这样可以为开发者提供详细的调试信息。
它的核心思想是:给定一个需要打桩的目标函数,创建一个包装函数,它的原型和目标函数一样。使用某种特殊的打桩机制,你就可以欺骗系统调用包装函数而不是目标函数了。包装函数通常会执行它自己的逻辑,然后调用目标函数,再将目标函数返回值传递给调用者。
打桩可以发生在编译时,链接时,或当前程序被加载和执行的运行时。
编译时打桩
我们用下面这个程序作为例子,我们的目标时用打桩来追踪对malloc和free的调用:
1 | // int.c |
我们可以通过头文件中指示预处理器用对相应包装函数的调用替换对目标函数的调用:
1 | ylin@Ylin:~/Program/test$ gcc -DCOMPILETIME -c mymalloc.c |
其中-DCOMPILETIME是条件编译的开关,当我们启用它时,相当于对所有编译文件#define COMPILETIME,这个时候我们的包装函数就是生效的,它会替换我们的目标函数,从而实现编译时的库打桩。
链接时打桩
Linux的静态链接器支持使用--wrap f的标志来进行链接时的打桩。这个标志链接器,将对符号f的引用解析为__wrap_f,把对符号__real_f的引用解析为f。因此我们可以写出我们用于链接时打桩的包装函数。
1 | //mymalloc.c |
然后我们将源文件编译成可重定位的目标文件:
1 | ylin@Ylin:~/Program/test$ gcc -DLINKTIME mymalloc.c -c |
然后再将其链接为可执行文件:
1 | ylin@Ylin:~/Program/test$ gcc -Wl,--wrap,malloc -Wl,--wrap,free -o intc int.o mymalloc.o |
其中-Wl,option1,option2,...则是将option作为参数传递给静态链接器。从而实现链接时的库打桩。
运行时库打桩
编译时打桩我们需要能够访问程序的源代码,链接时打桩我们需要能够访问程序的可重定位对象文件。不过,我们可以通过一种机制实现在运行时打桩,它只需要能够访问可执行文件。这个机制的原理基于动态链接器的LD_PRElOAD环境变量
如果LD_PRELOAD环境变量被设置为一个共享库路径名的列表(以空格或符号分隔),那么当你加载和执行一个程序,需要解析未定义的引用时,动态链接器会先搜索LD_PRELOAD库,然后再搜索其他的库。基于这个机制可以实现对任意共享库的任何函数进行打桩。
我们重写一份对malloc和free的包装函数(我们使用dlsym来返回指向libc函数的目标函数),并将其打包为共享库,通过修改LD_PRELOAD来劫持目标函数:
1 |
|
然后我们将其编译成共享库用于接下来的调用:
1 | ylin@Ylin:~/Program/test$ gcc -DRUNTIME -shared -fpic -o mymalloc.so mymalloc.c -ldl |
我们正常编译并运行主程序,会发现没有打桩行为:
1 | ylin@Ylin:~/Program/test$ gcc -o intc int.c |
可是我们可以通过修改动态链接的LD_PRELOAD实现运行时的打桩:
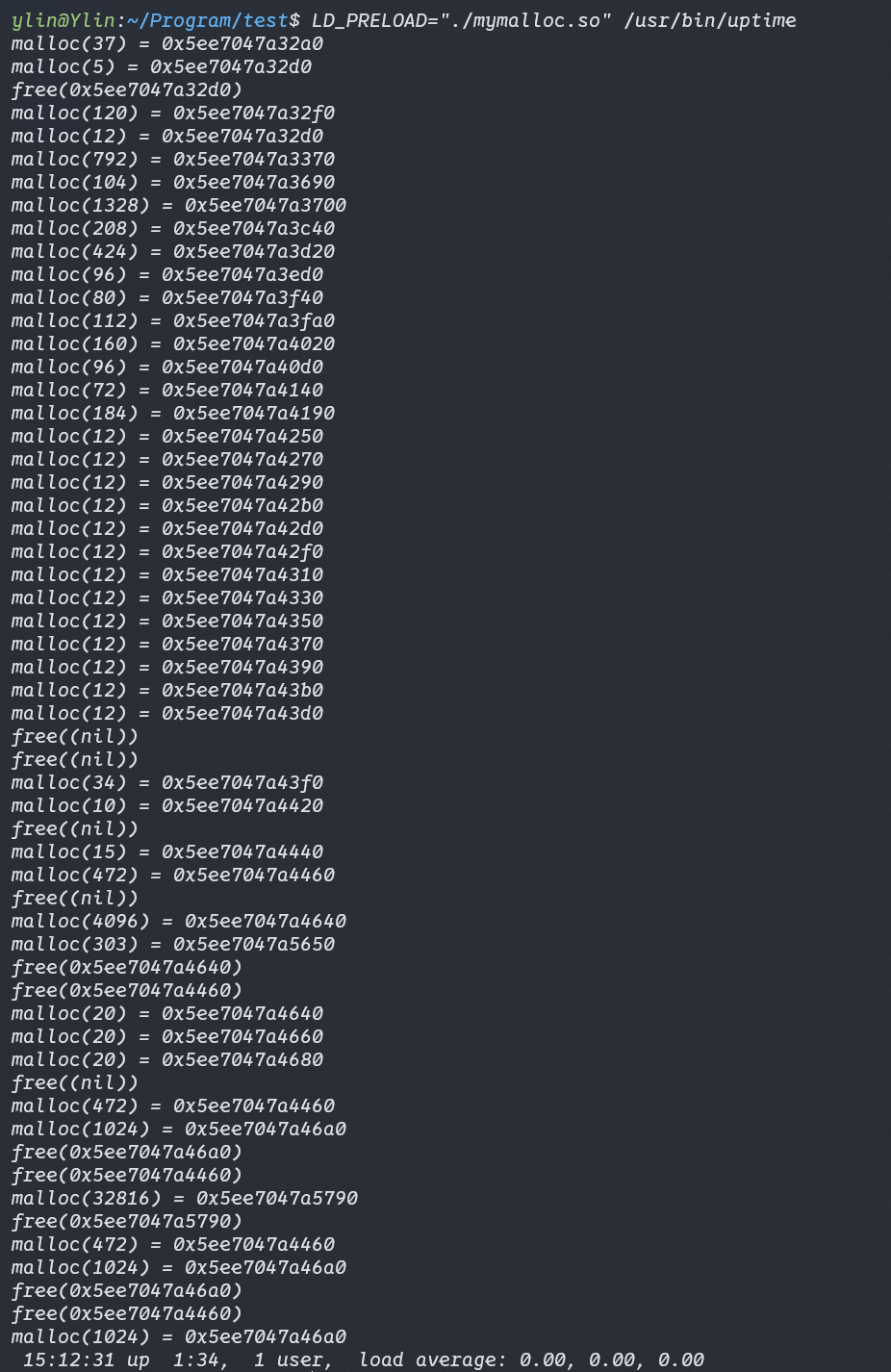
1 | ylin@Ylin:~/Program/test$ LD_PRELOAD="./mymalloc.so" ./intc |
不过实际上这里遇到了问题,我们修改了printf,改用了系统调用write从而避免printf内部实现用到malloc从而导致无限递归。这样我们实现了运行时的库打桩,我们甚至可以利用它去对任何程序的库函数进行调用打桩: