接下来我们要探讨学习一下符号解析和重定位实现的原理。
符号解析
连接器解析符号引用,实际上就是将每个引用,和它输入的可重定位目标文件的符号表中的一个确定的符号定义关联起来。当局部符号的引用和引用定义在相同模块的时候,符号解析简单明了。编译器只允许每个模块中每个局部符号只有一个定义,因此编译器要确保它们又唯一的名字。
不过,对于全局符号的引用解析就十分难以处理。当编译器遇到一个不是在当前模块定义的符号时,会假设这个符号已经被其他模块定义了,生成一个链接器符号表条目,将它交给链接器处理。如果链接器在它的任何输入模块中都找不到这个被引用的符号的定义,就会报错。比如我们尝试编译这个程序:
1 | void foo(); |
编译器会毫无障碍的编译,但是链接器却无法解析对foo的引用:
1 | ylin@Ylin:~/Program/test$ gcc test.c -o test -Wall -Og |
因此对于全局符号的处理比较困难,而且可能会出现多个目标文件定义相同名字的全局符号。此时,链接器要么选出一个定义抛弃其他定义,要么就给出一个错误。
链接器如何解析多重定义的全局符号
链接器的输入是一组可重定位目标模块。每个模块定义一组符号,有的是局部的(只对本地模块可见),有的是全局的(对其他模块也可见)。但是如果多个模块的定义了同名的全局符号,Linux编译系统会怎么做?
在编译时,编译器向汇编器输出每个全局符号,或是强或是弱,而汇编器把这个信息隐含地编码在可重定位的目标文件的符号表里。函数和已初始化的全局变量是强符号,未初始化的全局变量是弱符号。
Linux链接器会根据以下规则来处理多重定义的符号名:
- 不允许有多个同名的强符号
- 如果有一个强符号和多个弱符号同名,那么选择强符号。
- 如果有多个弱符号同名,那么从这些弱符号中任意选择一个
我们可以看下各个规则的具体表现:
- 规则一
1 | //1.c |
1 | ylin@Ylin:~/Program/test$ gcc -o prog 1.c 2.c |
这是因为强符号main被定义了多次,造成了冲突。下面也是
1 | //1.c |
1 | ylin@Ylin:~/Program/test$ gcc -o prog 1.c 2.c |
这里是因为被初始化的全局变量(强符号)x出现了多次,造成冲突。
- 规则二
1 | //1.c |
1 | ylin@Ylin:~/Program/test$ gcc -o prog 1.c 2.c |
这里虽然没有造成冲突,但是可以看到另一个模块对x的使用,修改了它的值。
- 规则三
1 | //1.c |
1 | ylin@Ylin:~/Program/test$ gcc -o prog 1.c 2.c |
结果和上面基本一致,但是我们并不知道最终使用了哪个符号,因为它们都是弱符号,是随机的。
当然现代的编译器为了避免多重定义的全局符号给我们带来的错误,往往在编译时,会开启GCC-fno-common选项,以保证遇到多重定义的全局符号时,会发生错误,无法通过链接。
在上一篇中我们提到了编译器会按规则将符号分配到COMMON或.bss,但是我们并不清楚为什么要这样做。现在我们知道了,在编译器翻译一个模块时,对于一个弱全局符号,它并不知道其他模块是否也定义了相同的符号。如果是的话,它无法预测链接器会使用多重定义中的哪一个,所以编译器将它这个弱全局符号放入COMMON中,交给链接器来决定。如果这个符号被初始化为0的话,那么它就是一个强符号,编译器就可以直接将它分配为.bss。相似的,对于静态变量(不用考虑多重定义),也是如此放入.bss或.data。
与静态库链接
到目前为止,我们都是假设链接器会读取一组可重定位目标文件,并将其链接起来,形成一个输出的可执行文件。实际上,所有的编译系统都支持一种机制——把所有相关的目标模块打包成为一个单独的文件,被称为静态库。当链接器要构造一个输出的可执行文件时,它只会复制静态库中被程序引用的目标模块。这么做有以下好处:
- 如果将模块合并到一个可重定位目标文件中,会导致程序每次链接都会包含一份完整的标准库。其中大部分的模块并不会被使用,这导致程序占用的磁盘空间会更大。
- 如果将标准函数内联至编译器,这虽然很便捷。但是会导致编译器开发的难度更大。且每次标准库的更新都需要修改编译器
- 如果为每个标准函数都创建一个独立的可重定位文件,将他们放在一个目录下。这会导致链接时需要大量的显式链接合适模块到可执行文件中。
所以链接库的概念被提出来。相关的函数可以被编译为独立的目标模块然后封装在一个单独的静态库文件。然后应用程序可以在命令行中指定单独的文件名字来使用这些在库中定义的函数。
在链接时,链接器将只复制被程序引用的模块,这就减少了可执行文件在磁盘和内存中的大小。且减少了程序员对库文件引用次数。
在Linux中,静态库以一种称为存档的特殊文件格式存放在磁盘中。存档文件时一组连接起来的可重定位目标文件集合,它的头部来描述每个成员目标文件的大小和为止。存档文件的后缀为.a
我们可以简单的实现一下这个过程:
1 | //addvec.c |
然后我们用这两个函数创建一个静态库:
1 | ylin@Ylin:~/Program/test$ gcc -c addvec.c multvec.c |
然后我们可以利用这个静态库来编写我们的程序,来验证是否只调用了我们需要的目标模块:
1 |
|
使用gcc -static -o prog main.o -L . -ltest编译(其中-static是静态链接,-L指定静态库的查询目录,-ltest是./libtest.a的缩写),我们使用:
1 | ylin@Ylin:~/Program/test$ objdump -d prog | grep "addvec" |
发现程序中并没有addvec目标模块,静态库的链接很好的完成了工作。整个过程我们可以用这个图来大致的表现。
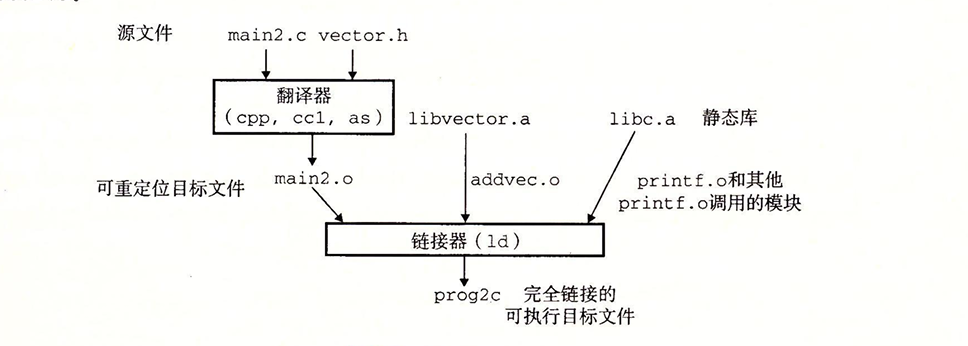
链接器如何使用静态库来解析引用
解释一下静态库使用的原理和可能遇到的一些问题。
Linux链接器在解析外部引用的时候,是从左往右按照编译器驱动程序命令行上的顺序来扫描,可重定位目标文件和存档文件(驱动程序会自动将源程序文件翻译成可重定位目标文件)。在扫描中,链接器会维护一个可重定位目标文件中的集合E(该集合文件中的目标文件会被链接成可执行文件),一个未解析的符号集合U(引用了但是尚未定义的符号),一个在前面的输入文件中已定义的符号集合D。初始时,E、U、D均为空:
- 对于命令行上的每个输入文件
f,链接器会判断它的类型,是目标文件还是存档文件。如果是目标文件,则将其放入E中,然后修改U和D来反映f中符号定义和引用,并继续下一个输入文件。 - 如果
f是一个存档文件,那么链接器就尝试匹配U中未解析的符号和由存档文件成员定义的符号。如果某个存档文件成员定义了一个符号来解析U中的一个引用,那么就将m加到E中,并且修改U和D来反映m的符号定义和引用。对存档文件中的每一个程序进行这个尝试,知道U和D都不再变化。此时不包含在E中的目标文件被丢弃。开始处理下一个输入文件。 - 如果链接器处理完所有的输入文件之后,U是非空的,链接器就会输出一个错误并停止。反之,则合并重定位E中的目标文件,构建输出的可执行文件。
不过因此,命令行上的库和目标文件的顺序也很重要。在命令行中,如果定义一个符号的库出现在引用这个符号的目标文件之前,那么引用就不会被解析,链接会失败。对于存档文件之间的顺序也是如此。如果一个库a中的引用在另一个库b中被定义,那么要先a后b。反之,如果库直接都是相互独立的,就可以不在乎输入顺序。
重定位
当链接器完成了符号解析,代码中的每个符号引用和它的符号定义(即目标模块中的符号表条目)就会被关联起来。此时,链接器就知道它的输入目标模块中的代码节和数据节的确切大小。现在就可以重定位操作了,在这个步骤中,将合并输入模块,并为每个符号分配运行时的地址。
重定位节和符号定义:
在这一步中,链接器将所有相同类型的节合并为同一类型的新的聚合节。然后链接器将运行时内存地址赋给新的聚合节,赋给输入模块定义的每个节,以及赋给每个节的每个符号。当这一步完成时。程序中的每条指令和全局变量都有唯一的运行时内存地址。
重定位节中的符号引用:
在这一步中,链接器修改代码节和数据节中对每个符号的引用,使得他们指向正确的运行时的地址。要执行这一步,链接器依赖于可重定位目标模块中称为重定位条目的数据结构,我们接下来将会描述这种数据结构。
重定位条目
当汇编器生成一个目标模块时,它并不知道数据和代码在运行时会被存放在内存中的哪个位置。也不知道模块引用的外部定义的函数或全局变量的位置在哪里。所以,当汇编器遇到最终位置未知的目标引用,他就会生成一个重定位条目(用来为链接器修正未知提供“导航”),用来告诉链接器,在合并目标模块时如何修改这个引用。代码的重定位条目存放在.rel.text,数据的重定位条目存放在.rel.data
下面是一个典型的重定位条目格式:
1 | typedef struct{ |
- offset:需要被修改的引用的节偏移
- type:如何修改新的引用
- symbol:被修改的引用应该指向的符号
- addend:一个有符号常数,个别类型的重定位需要使用它对被修改引用的值做偏移调整
ELF定义了32中不同的重定位类型,但是我们需要考虑两种最常见的类型:
R_X86_64_PC32:
重定位一个使用32位PC相对地址的引用。一个PC相对地址就是据PC当前运行时值的偏移量。当CPU执行一条使用PC相对寻址的指令时,他就将在指令中编码的32位值加上当前的PC值,得到有效地址,PC值通常是下一条指令在内存中的地址
R_X86_64_32:
重定位一个使用32位绝对地址的引用。通过绝对寻址,CPU直接使用在指令中编码的32位值作为有效地址
重定位符号引用
根据重定位算法,来分析一下重定位的过程。下面展示重定位算法的伪代码,为了方便表示,假设每个节s是一个字节数组,每个重定位条目r都是一个类型为Elf64_Rela的结构。用ADDR()来获取对应的运行时的地址:
1 | for (section:s){ |
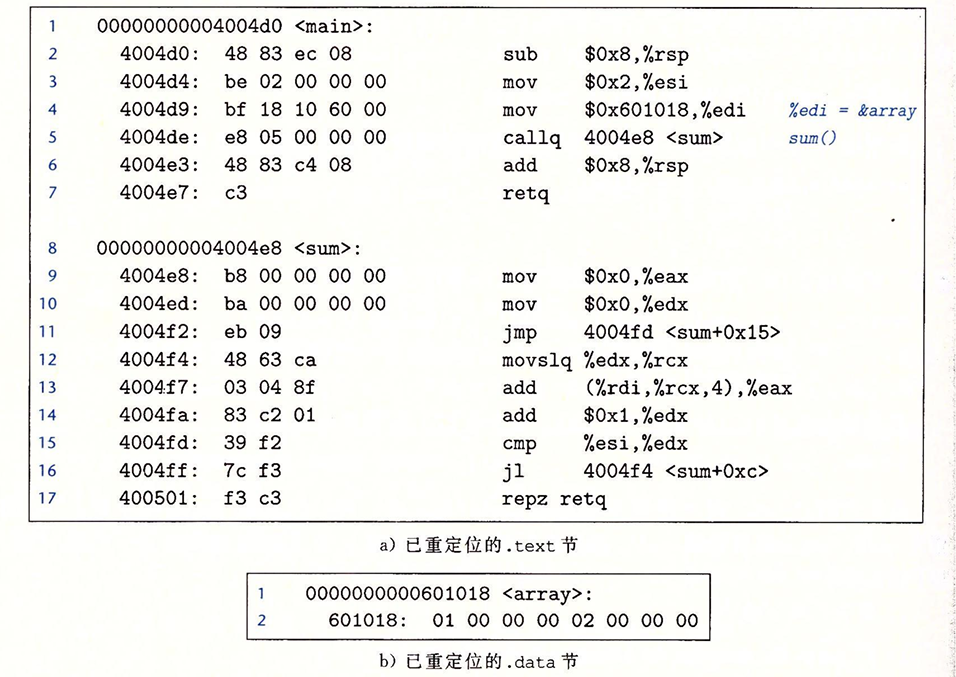
以下面这个反汇编代码为例,我们来分析一下链接器是怎么重定位这些引用的:

重定位PC相对引用
第6行,call开始于节偏移值为0xe的地方,包括1字节的操作码0xe8,还有四个字节的占位符。其中sum的重定位条目r为:
1 | r.offset = 0xf |
这些字段告诉链接器修改开始于偏移量0xf的32位PC相对引用,在运行时它会指向sum例程。此时链接器已知:
1 | ADDR(s) = ADDR(.text) = 0x4004d0 |
我们重定位的过程应该是这样的:
1 | refaddr = ADDR(s) + r.offset |
最终得到4004de: e8 05 00 00 00 callq 4004e8 <sum>
重定位绝对引用
第4行,mov开始于节偏移值位0x4的地方,包括1字节的操作码0xbf,还有四个字节的arrary地址的占位符。其中array的重定位条目r为:
1 | r.offset = 0xa |
这些字段告诉链接器要修改从偏移量0xa开始的绝对引用,这样在运行时它会指向arrary的第一个字节。此时链接器已知:
1 | ADDR(r.symbol) = ADDR(array) = 0x601018 |
我们重定位的过程为是这样的:
1 | *refptr = (unsigned) (ADDR(r.symbol) + r.addend) |
最终得到4004d9: bf 18 10 60 00 mov $0x601018,%edi。最终的效果如下: