我们把之前的SEQ结构已经实现了,可是为了更好的符合流水线执行的特性,为我们需要对顺序的SEQ处理器做一点小的改动,我们需要将PC的计算拿到取指阶段。然后在不同的阶段之间留下流水线寄存器来保存状态。
Y86-64的流水线实现
SEQ+:重新安排计算阶段
我们要把更新PC的阶段放在取值阶段,在第一个时钟周期开始执行。这样可以保证每个周期都能做到去除指令,从而实现流水线运作的状态。我们把这种改动后的结构称为SEQ+
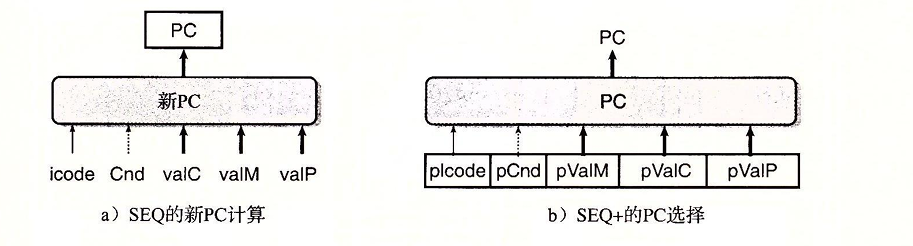
我们可以注意到,在SEQ中PC的计算是根据当前时钟周期中的信号值和数据机型计算的。而在SEQ+中PC的计算则是根据上一个时钟周期产生的信号计算得到的。我们可以在下面的整体架构中起初的看到这一点
要特别指出,在SEQ+中并没有设置硬件来保存当前的PC,而是根据前一条指令保存下来的状态信息动态的计算出PC
插入流水线寄存器
这是更新后的SEQ+架构,但是我们需要向其中插入流水线寄存器,以保存每个阶段的状态信息和数据
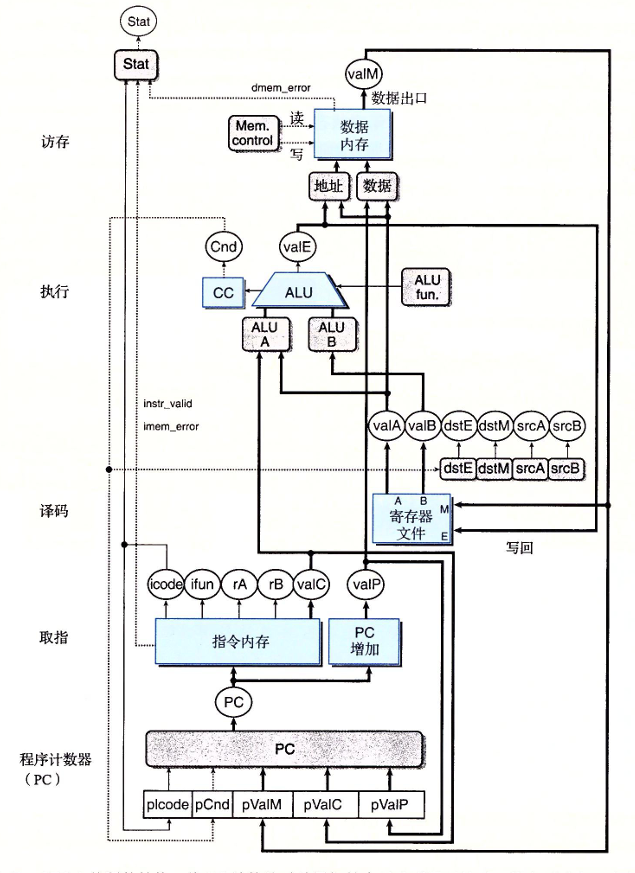
我们将流水线寄存器插入之后,可以得到PIPE-处理器,两者的硬件架构实际上差不多,但是信号的含义并不完全相同,我们接下来介绍一下其架构功能:
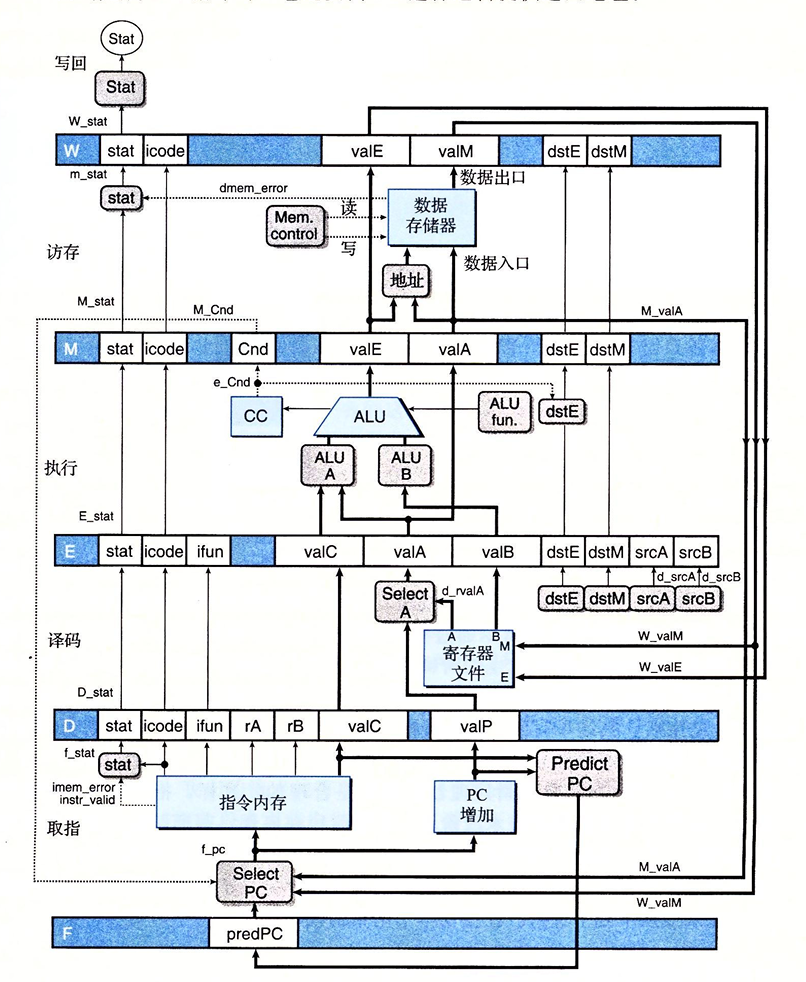
流水线寄存器的功能如下:
- F 保存程序计数器的预测值
- D 位于取指和译码阶段之间。它保存关于最新取出的指令的信息,即将由译码阶段进行处理
- E 位于译码和执行阶段之间。它保存关于最新译码的指令和从寄存器文件中读出的信息,接下来交给执行阶段处理
- M 位于执行和访存阶段之间。它保存最新执行的指令的结果,即将由访存阶段进行处理。它还保存关于用于处理条件转移的分支条件和分支目标的信息
- W 位于访存阶段和反馈路径之间,反馈路径将计算出来的值提供给寄存器文件写,当完成ret指令时,它还要向PC选择逻辑提供返回地址
在PIPE-处理器中我们流水线执行指令的效果是这样的:
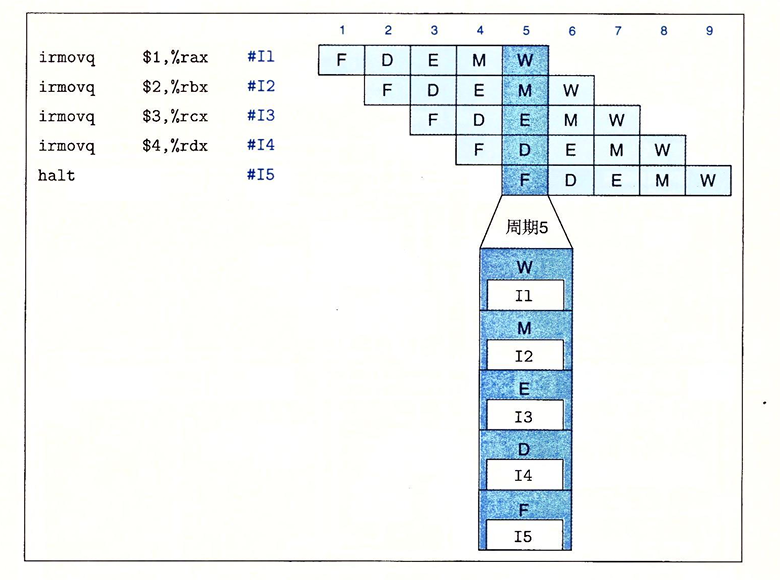
对信号进行重新排列和标号
在之前的SEQ和SEQ+架构中,我们在每个时刻只处理一条指令,因此每个信号值在同一个时刻的都是唯一的值。在流水线化的设计中,不同的阶段使用和保存的是不同的信号值所以我们需要加以区分。并使用重新的命名机制。我们将流水线寄存器中的信号前面用大写的前缀标识,如D_atat E_stat M_stat W_stat。对于从一个阶段中计算出来的值,我们用小写开头来标识,不过特别注意实际状态Stat是由写回阶段计算出来的。
下面我们需要注意几个特别的地方:
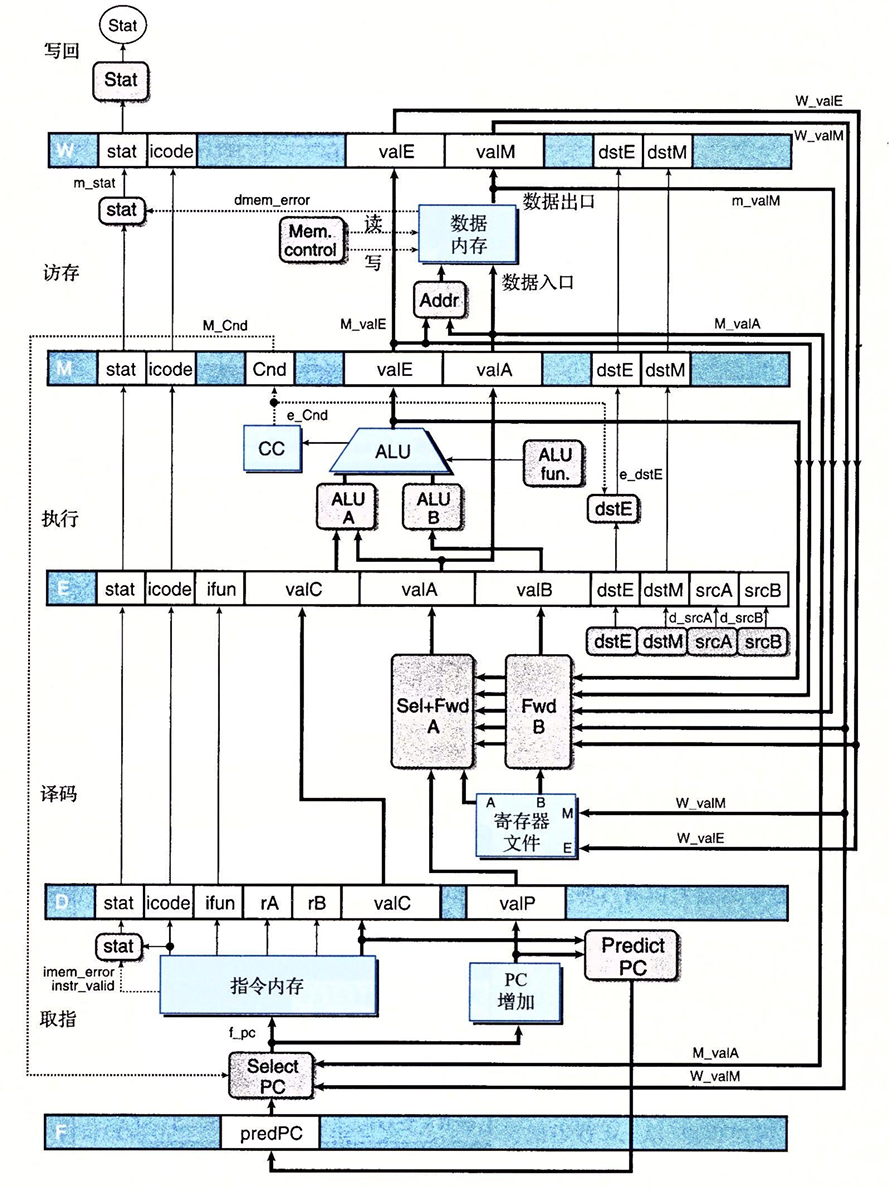
- 在译码阶段会产生dstM和dstE的值,他们指明valE和valM的目的寄存器。在SEQ+中我们可以直接将信号连到写端口地址输入。在PIPE-中,会在流水线中一直携带这样的信号穿过执行和访存阶段,直到写回才送到寄存器文件中。这样是为了确保写端口地址和数据输入最终是来自同一条指令。不然写回的数据是写回阶段的,但是给定的写端口却是取值阶段的。我们要避免这种情况
- PIPE-中一个块在相同的表示形式的SEQ+中是没有的,那就是译码阶段中的
SelectA块。这个块会从寄存器文件中的valA和流水线寄存器中D中的valP中的选出一个值作为流水线寄存器E的valA值。这个块用来减少携带给流水线寄存器E和M的状态数量。在所有的指令中,只有call在访存阶段中需要valP的值,只有跳转指令在执行阶段需要valP,而又恰好这些指令都不需要从寄存器文件中读出来的值。所以我们用这个块来合并这两个信号,将它作为valA携带穿过流水线,从而可以减少流水线寄存器的状态数量。 - 不同阶段之间的流水线寄存器中包括一个状态码stat字段,开始时是在取指阶段计算出来的,但是在访存阶段可能因为错误访问导致修改状态。所以最好的办法就是让与每条指令关联的状态码和指令一起通过流水线,像图中一样。
预测下一个PC
在PIPE-设计中我们通过流水线化的设置使得每个时钟周期都发送一条新的指令,也就是说每个时钟周期都有一条新的指令进入执行阶段并最终完成。但是这要求我们取出一条指令之后能够立马确定下一条指令的文职。但是,当我们取出的是ret或者条件分支指令的时候,我们需要几个周期后才能确定返回的地址。
除了条件转移指令和ret以外,根据取指阶段中计算出来的信息,我们都能够确定下一条指令的地址。对于call和jmp而言,下一条指令的地址就是指令中的常数字valC,而对于其他指令来说就是valP。因此,我们对于这些指令都可以实现PC的预测。
而对于条件转移,我们既可以预测选择了分支,新PC为valC;也可以预测没有选择分支,新PC为valP。这种情况叫做分支预测,我们会在之后讨论这个问题。
对于ret指令的PC值的预测。通条件转移不同,此时可能的返回值是无限的,因为返回地址是位于栈顶的字,其可能是任意的。在设计中,我们不会试图对返回地址进行预测。只是简单的暂停处理新指令,直到ret指令完成写回,我们之后会讨论这个内容。
PIPE-的取指阶段,负责预测PC的下一个值,以及为取指选择实际的PC。其中标号为”Predict PC”的块会从PC增加器计算出的valP和取出指令中得到的valC中进行选择。然后将这个值放在流水线寄存器F中,作为程序计数器的预测值。
流水线冒险
将流水线技术引入一个带反馈的系统,当像相邻指令间存在相关时则会出现问题。这些相关有两种形式:
- 数据相关:下一条指令会用到这一条指令计算出的结果
- 控制相关:一条指令要确定下一条指令的未知。如执行跳转、调用或返回指令时。
这些相关可能会导致流水线产生错误,我们称之为冒险(分为数据冒险和控制冒险,我们先考虑数据冒险),这里我们可以了解一下不同程序状态可能产生的冒险的类型和状态:
- 程序寄存器:寄存器文件的读写是在不同的阶段进行的,导致不同指令之间可能出现不希望的相互作用
- 程序计数器:更新和读取程序计数器之间的冲突会导致控制冒险。当我们的取指阶段在取下一个指令之前,正确预测了程序计数器的新值时,就不会产生冒险。预测错误的分支和ret指令需要特殊处理。
- 内存:对数据内存的读和写都发生在访存阶段。在一条读内容的指令之前,我们需要将所有写内存的指令都完成,以免读写的状态不一样。同时我们要确保写入的内存空间不会影响指令代码,所以我们在此禁止,指令自我修改的情况。
- 条件寄存器:在执行阶段中,整数操作会写这些寄存器。条件传送指令会在执行阶段以及条件转移会在访存阶段读这些寄存器。在条件传送或条件转移到达执行阶段前,整数操作就已经完成了这个阶段。所以不会发生冒险
- 状态寄存器:指令经过流水线时,会影响程序状态。我们采用流水线中的每个指令都与一个状态码关联的机制,使得发生异常时,处理器可以有条理的停止。
我们用图片简单的演示一下冒险的发生:
上面展示了不同情况下可能发生冒险的情况及其原因。我们可以用以下几种方法来避免冒险:
用暂停来避免数据冒险
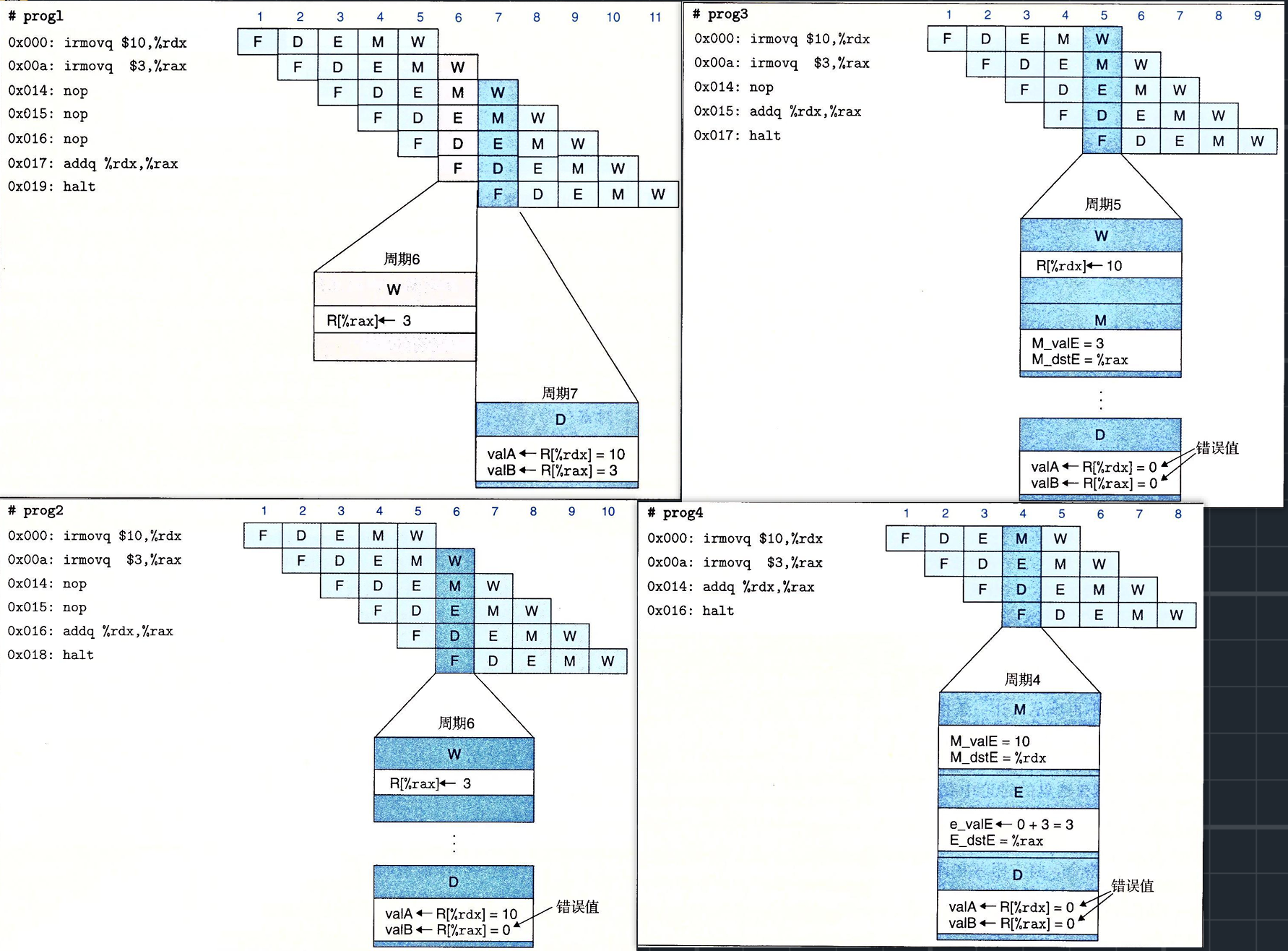
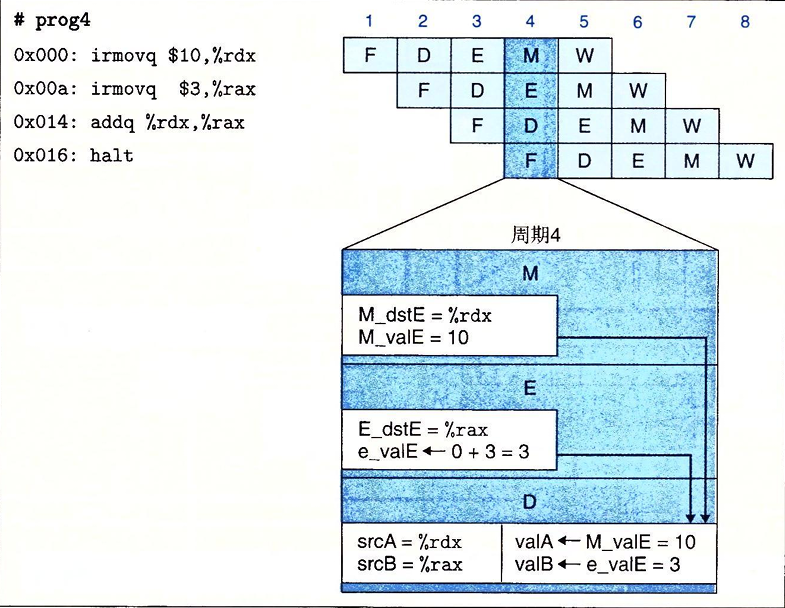
暂停时,处理器会停止流水线中一条或多条指令,直到冒险条件不再满足。让一条指令停顿在译码阶段,直到它的原操作书通过了写回阶段,这样我们的处理器就能避免数据冒险。例如:
当addq指令处于译码阶段时,流水线控制逻辑发现执行、访存或写回阶段中至少有一条指令会更新寄存器rdx或rax。处理器不会让addq指令带着错误的结果通过,于是会暂停这个指令,将其阻塞在译码阶段。直到得到正确的源操作数,然后沿着流水线继续执行。当然addq指令被阻塞在译码阶段时,halt指令也被阻塞在取指阶段,我们通过保持PC不变来实现这一点。
总之,暂停技术就是让一组指令阻塞在他们所处的阶段,而允许其他指令继续通过流水线。我们实现所用的方法是:每次要把一条指令阻塞在译码阶段,就像执行阶段插入一个气泡,气泡就像一个自动产生的nop指令——它不会改变任何程序状态。关于其详细机制,我们之后会讨论
在实际的指令中,像这样的数据冒险十分常见。如果我们频繁的使用暂停,会导致流水线的效率下降,严重降低了整体的吞吐量
用转发避免数据冒险
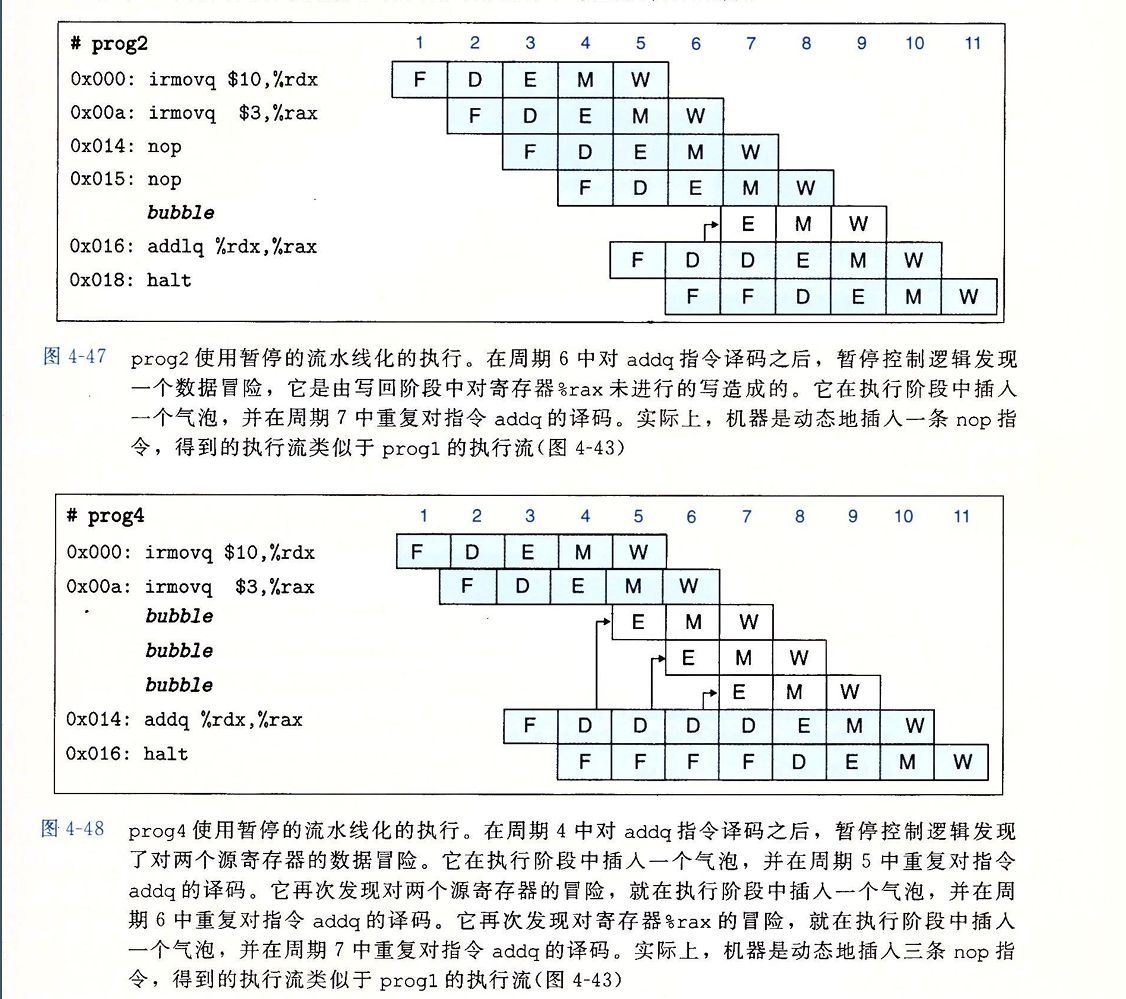
PIPE-的设计是在译码阶段从寄存器文件中读入原操作数。但是这些源操作数只有在写回阶段才能进行。与其等其暂停写入,不如直接将要写的值传到流水线寄存器E作为源操作数。这种将结果值直接从一个流水线阶段传到较早阶段的技术称为数据转发。例如:
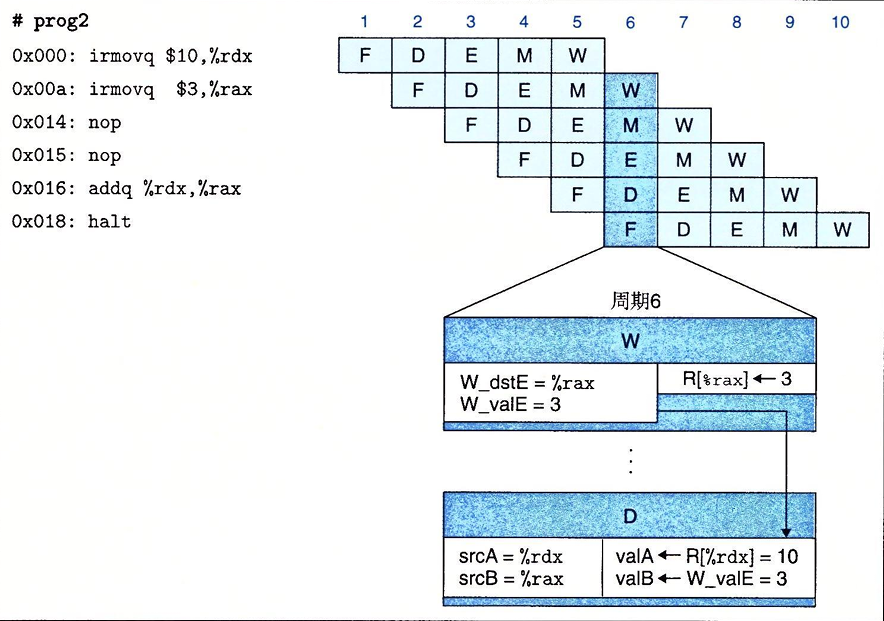
不仅如此,为了充分利用数据转发技术,我们还可以将访存阶段对寄存器没有完成的写和执行阶段新计算出来的值转到译码阶段。
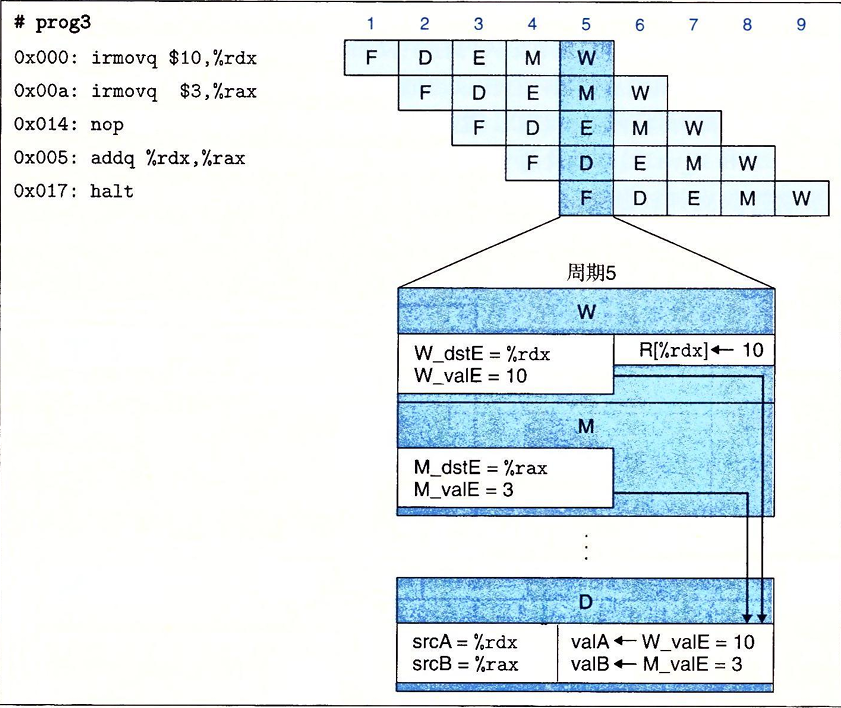
总结一下,我们可以将还没有写回的信号(W_valM,W_valE)转发到我们的E端口。也可以将刚从内存中读出的信号m_valM转发。也可以将尚未进行访存的信号M_valE进行转发。或者是将刚计算出来的e_valE进行转发。也就是说,我们有五个转发源(e_valE,m_valM,M_valE,W_valE,W_valM)和两个不同的转发目的(E_valA,E_valB)
我们在硬件层面上实现转发的功能,从而得到我们最终的PIPE处理器架构,使得我们不用暂停流水线就能处理大多形式的数据冒险。
这就要求处理器在译码阶段能够检测转发需求,所以我们看到来自五个转发源的值反馈到译码阶段中两个标号为”Sel+Fwd A”和”Fwd B”的块。标号为”Sel+Fwd A”的块是”SelectA”功能和转发逻辑功能的组合。它允许流水线寄存器E的valA位已增加的程序计数器valP,从寄存器文件A端口读出的值,或者某个转发过来的值。
加载/使用数据冒险
有一类数据冒险不能简单的使用转发来解决。这是因为内存读在流水线中发生的比较晚,我们以下图为例。可以看到,我们在周期7想要将数据转发时,程序还没有访问到指定内存的值
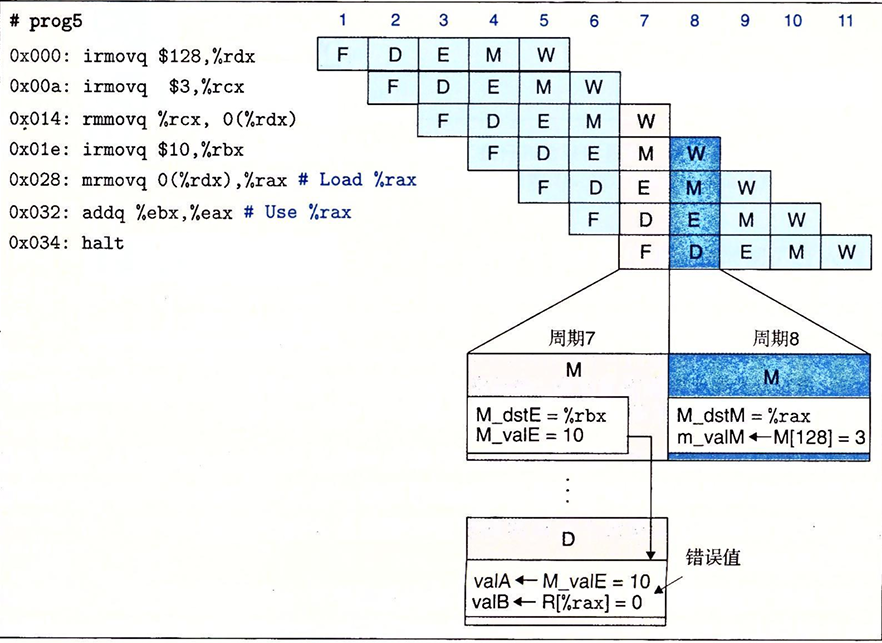
我们可以将暂停和转发结合起来,来避免加载/使用数据冒险。这个做法需要改变控制逻辑,但是我们可以使用现有的旁路路径。当流水线控制逻辑发现译码阶段的指令需要从内存中读取出来的结果是。它会将译码阶段中的指令暂停一个周期,导致执行阶段中插入一个气泡。从而实现避免数据冒险
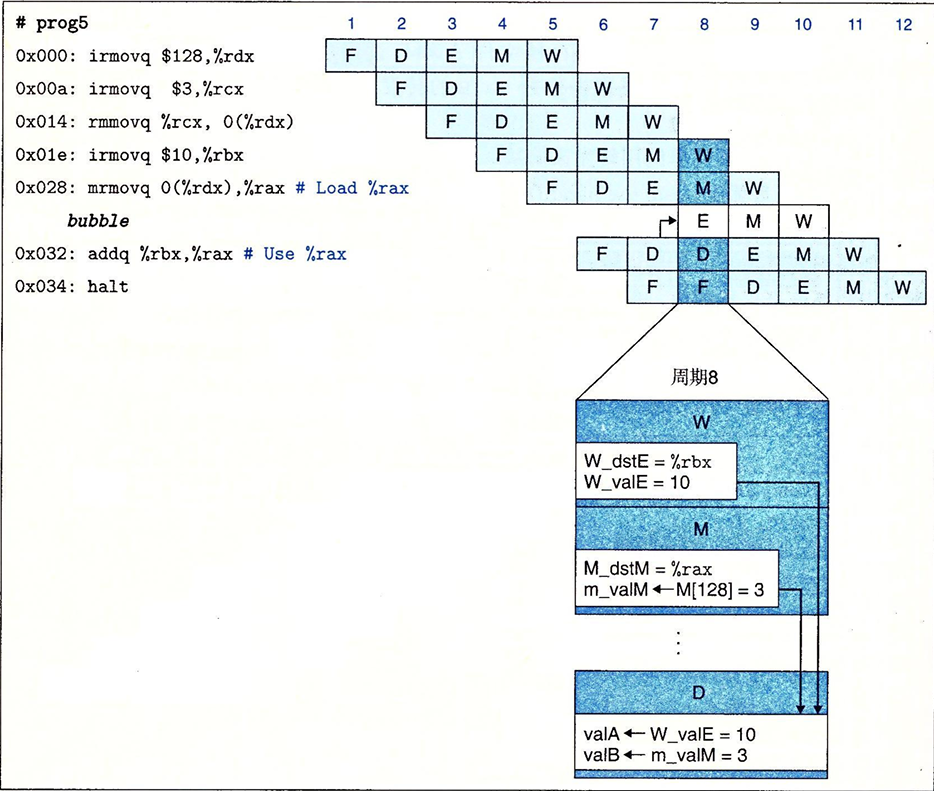
这种用暂停来处理加载/使用冒险的方法称为加载互锁。加载互锁和转发技术结合起来足以处理所有可能的数据冒险类型,因为加载互锁出现的情况有限,流水线的吞吐效率几乎不会受到影响
避免控制冒险
当处理器无法根据取指阶段来确定下一条指令的地址时,就会出现控制冒险。不过控制冒险指挥发生在ret指令和跳转指令,我们将简单谈论其处理方式。
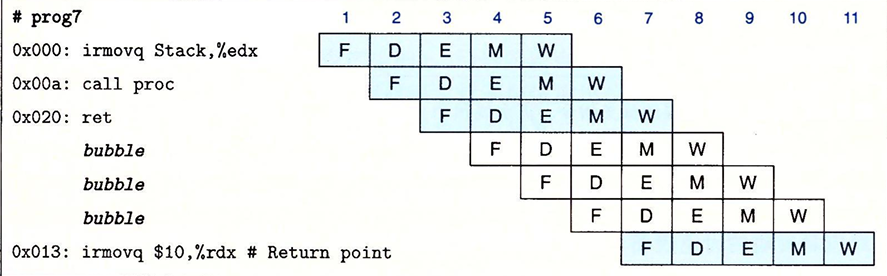
ret
ret控制冒险的处理比较简单,我们只需要在ret的译码、执行、访存阶段时,暂停流水线,在处理过程中插入三个气泡。当指令到达写回阶段,PC选择器就会选择返回地址作为指令的取指地址。从而避免控制冒险
分支错误预测
我们以一个汇编程序为例
1 | 0x000: xorq %rax,%rax |
处理器处理的流程如下图
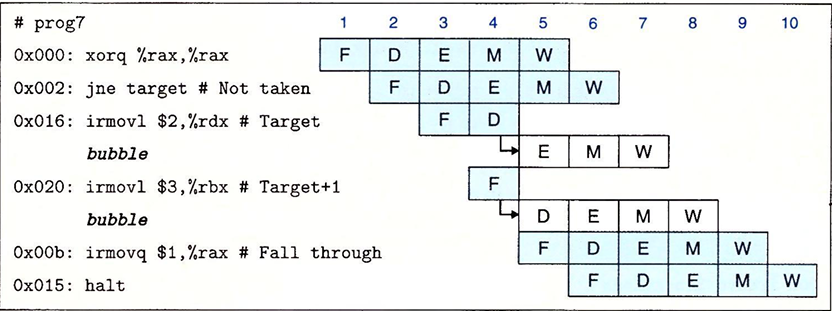
首先程序的预测分支逻辑会选择分支,于是在周期3中会把target指令进行取指。在周期4中,target进入译码,而target+1被取指,此时跳转指令会在执行阶段判断是否应该进行跳转。如果选择分支,则保持程序逻辑不变;如果不应该选择分支,我们则应该停止执行这两条命令(我们需要在下一个周期往译码和执行阶段插入气泡,并取消这两个错误的指令)。在周期5中,程序的条件码被改变,我们需要取消两条跳转预测指令,同时取指一条跳转指令后面的指令,从而避免了分支预测错误导致的控制冒险。
所以综上所述,通过暂停和往流水线中插入气泡的技术可以动态调整流水线的流程。我们对基本时钟寄存器设计的基本拓展可以实现暂停流水线,并向流水线控制逻辑一部分的流水线寄存器中插入气泡,从而实现避免控制冒险。