我们已经基本了解了Y86-64的指令集和汇编的用法,现在我们要尝试模拟处理器的硬件行为。这里描述一个称为SEQ的处理器,我们了解它的使用过程,并尝试构建它。
Y86-64的顺序实现
将处理组织成阶段
处理一条指令包括很多的操作和步骤,如果我们有序的将其进行划分。我们就可以得到一个顺序序列,所有的指令都可以按这个顺序进行处理,从而实现高效的流水线处理。我们可以将其划分为几个阶段:
- 取址:从内存读取指令字节,读取地址为当前PC的值。先取出指令指示符字节的两个四位部分:icode和ifunc,然后根据指令类型判断是否要取出寄存器指示符字节和8字节常数字。然后再按顺序计算当前指令的下一条指令的地址,将其作为下一次取指的PC。
- 译码:从寄存器文件中读入最多两个操作数,得到值valA和valB。读入的寄存器是rA和rB指明的寄存器。
- 执行:在执行阶段,ALU要么根据ifunc的值,计算内存引用的有效地址;要么增减栈指针。我们将得到的数据称为valE。同时执行阶段也可能会设置条件码,对于条件传送指令来说,这个阶段会检验条件码和传送条件(ifun),如果条件成立,就更新目标寄存器。同样的,对于跳转指令,这个阶段决定是否应该选择分支。
- 访存:该阶段将数据写入内存,或从内存中读出数据。读出数据称为valM
- 写回:写回阶段最多将两个结果写到寄存器文件
- 更新PC:将PC设置为下一条指令的地址
处理器会不停的执行这些阶段,从而实现执行指令的功能。
而现在的难点在于我们怎么将每一个指令转换成这些阶段内,以实现处理器的按阶段执行,我们需要好好处理一下。
OPq rrmovq irmovq
这几个指令的共同点在于计算了一个值,并将值存放在寄存器中。而OPq则代表四个整数操作,因为它们只有OPq操作和ifunc值是不一样的,所以我们统一处理。这里的Mx[]的x指的是从内存中读取的字节数。
| 阶段 | OPq rA rB | rrmovq rA rB | irmovq V rB |
|---|---|---|---|
| 取址 | icode:ifunc <– M1[PC] rA:rB <– M1[PC+1] valP <– PC+2 |
icode:ifunc <– M1[PC] rA:rB <– M1[PC+1] valP <– PC+2 |
icode:ifunc <– M1[PC] rA:rB <– M1[PC+1] valC <– M8[PC+2] valP <– PC+10 |
| 译码 | valA <– R[rA] valB <– R[rB] |
valA <– R[rA] | |
| 执行 | valE <– valB OP valA Set CC |
valE <– 0 + valA | valE <– 0+ valC |
| 访存 | |||
| 写回 | R[rB] <– valE | R[rB] <– valE | R[rB] <– valE |
| 更新PC | PC <– valP | PC <– valP | PC <– valP |
注意到并不是每个阶段都需要进行处理
rmmovp mrmovp
这两个指令都有访存阶段
| 阶段 | rmmovq rA D(rB) | mrmovq D(rB) rA |
|---|---|---|
| 取址 | icode:ifunc <– M1[PC] rA:rB <– M1[PC+1] valC <– M8[PC+2] valP <– PC+10 |
icode:ifunc <– M1[PC] rA:rB <– M1[PC+1] valC <– M8[PC+2] valP <– PC+10 |
| 译码 | valA <– R[rA] valB <– R[rB] |
valB <– R[rB] |
| 执行 | valE <– valB + valC | valE <– valB + valC |
| 访存 | M8[valE] <– valA | valM <– M[valE] |
| 写回 | ||
| R[rA] <– valM | ||
| 更新PC | PC <– valP | PC <– valP |
pushq popq
这个过程的实现相对复杂,同时pushq和popq的实现过程,正是上一篇中push %rsp和pop %rsp行为的答案
| 阶段 | pushq rA | popq rA |
|---|---|---|
| 取址 | icode:ifunc <– M1[PC] rA:rB <– M1[PC+1] valP <– PC+2 |
icode:ifunc <– M1[PC] rA:rB <– M1[PC+1] valP <– PC+2 |
| 译码 | valA <– R[rA] valB <– R[%rsp] |
valA <– R[%rsp] valB <– R[%rsp] |
| 执行 | valE <– valB + (-8) | valE <– valB + 8 |
| 访存 | M8[valE] <– valA | valM <– M8[valA] |
| 写回 | R[%rsp] <– valE | R[%rsp] <– valE R[rA] <– valM |
| 更新PC | PC <– valP | PC <– valP |
jXX call ret
这三个指令都有控制转移的处理,有跳转,所以我们放到一起来进行讨论
| 阶段 | jXX Dest | call Dest | ret |
|---|---|---|---|
| 取址 | icode:ifun <– M1[PC] valC <– M8[PC+1] valP <– PC+9 |
icode:ifun <– M1[PC] valC <– M8[PC+1] valP <– PC+9 |
icode:ifun <– M1[PC] valP <– PC+1 |
| 译码 | valB <– R[%rsp] | valA <– R[%rsp] valB <– R[%rsp] |
|
| 执行 | Cnd <– Cond(CC,ifun) | valE <– valB + (-8) | valE <– valB + 8 |
| 访存 | M8[valE] <– valP | valM <– M8[valE] | |
| 写回 | R[%rsp] <– valE | R[%rsp] <– valM | |
| 更新PC | PC <– Cnd ? valC : valP | PC <– valC | PC <– valM |
这里需要注意JXX的执行阶段,我们通过条件码和跳转条件来确定是否选择分支,并将其设置为位信号Cnd
SEQ的硬件结构
我们将指令组织成了6个阶段来进行,现在每个阶段我们使用一个硬件单元来负责这些处理。这样子,在每个时钟周期,一个硬件都可以完成一次处理。现在我们根据这张图介绍一下硬件单元和各个处理阶段的关联:
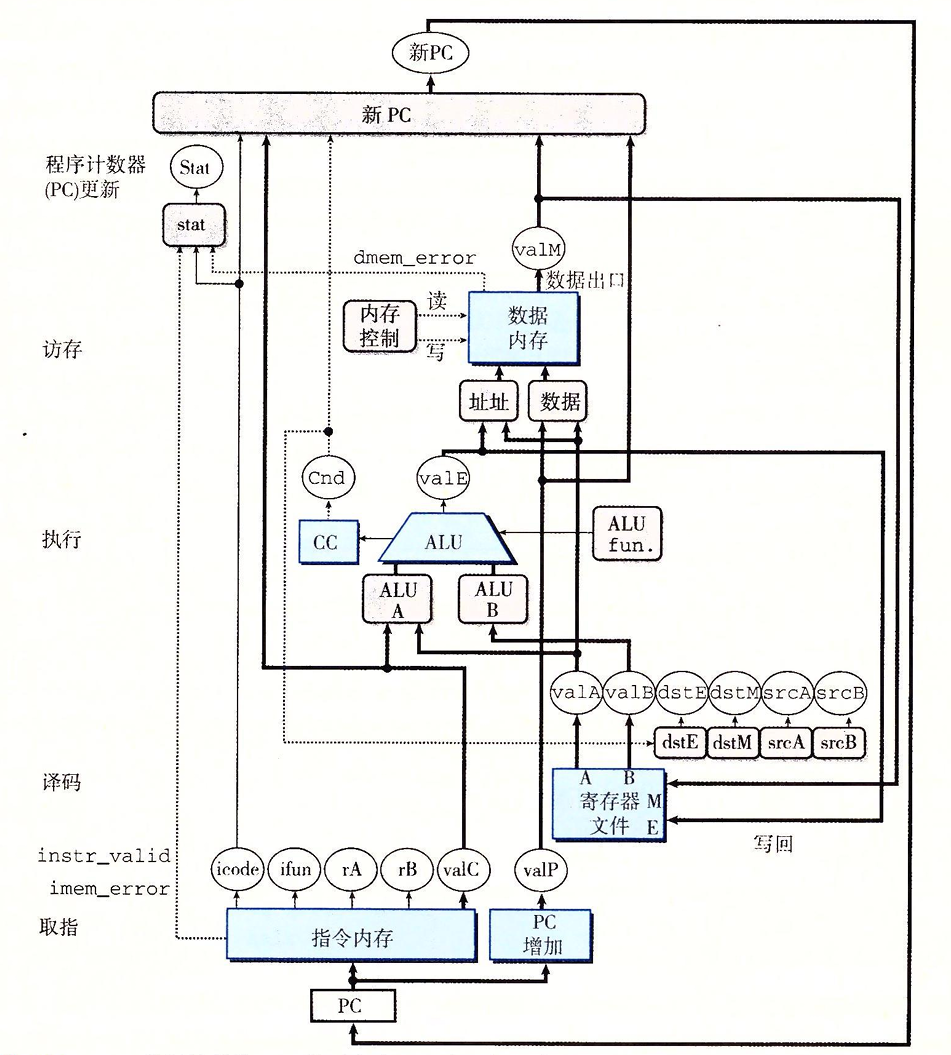
- 取指:将PC作为指令内存的地址,读取指令的字节。使用PC增加器计算valP,即增加后的PC
- 译码:寄存器文件有两个读端口A和B,从这两个端口同时读寄存器值valA和valB
- 执行:执行阶段会根据指令的类型,将ALU用于不同的目的。同时计算条件码的新值。并根据跳转类型和条件码设置分支信号Cnd
- 访存:在访存时,数据内存读出或写入一个内存字。
- 写回:寄存器文件有两个写端口。端口E用来写ALU计算的值,端口M用来写从数据内存中得到的值
- PC更新:程序计数器的新值选择自:valP,下一条指令的地址;valC,调用指令或跳转指令指定的目标地址;valM,从内存读取的返回地址
我们可以这样笼统的表现我们的一个计算过程:
| 阶段 | 计算 |
|---|---|
| 取址 | icode:ifunc rA:rB valC valP |
| 译码 | valA <– srcA valB <– srcB |
| 执行 | valE Cond.codes |
| 访存 | Read/Write |
| 写回 | E port <– dstE M port <– dstM |
| PC更新 | PC |
SEQ的时序
我们从软件层面上的习惯会使得我们认为,这几个阶段是从上到下按顺序执行的。但是SEQ作为一个硬件模型,它的操作运行并不一样。一个时钟变化会引发一个经过组合逻辑的流,从而执行整个指令。我们不妨分析一下这个行为。
SEQ的硬件实现主要由组合逻辑和两种存储器设备:时钟寄存器(程序计数器和条件码寄存器),随机访问存储器(寄存器文件,指令内存和数据内存)。组合逻辑则不需要任何时序和控制,只要输入变化了,值就通过逻辑电路传播。
我们由四个硬件单元需要对他们的时序进行明确的控制——程序计数器,条件码寄存器,数据内存和寄存器文件。这些单元通过一个时钟信号来控制,它触发将新值装载到寄存器,以及将值写到随机访问存储器。
我们可以看看这几个硬件单元的不同:
- 每个时钟周期,程序计数器都会装载新的指令地址。
- 只有在进行整数运算指令时,才会装载条件码寄存器。
- 只有在执行
rmmovq pushq call时,才会写数据内存。 - 寄存器文件的两个写端口允许每个时钟周期更新两个程序寄存器,我们可以通过特殊ID 0xF来作为端口地址,表明端口不进行写操作
也就是说实际上,每个硬件的功能是同时进行的,且互不干扰的。我们用它来执行我们的程序,这就对我们的指令有着“从不回读”的要求。这意味着处理器从来不用为了完成一条指令的执行而去读由该指令更新的状态。
以pushq %rsp为例,如果是先将%rsp-8,在将更新后的%rsp作为写操作的地址。这就是错误的,为了执行内存操作,他需要先从寄存器中读更新过的栈指针,这是错误的。因为在硬件各个阶段同步执行下,没有一个指令可以即设置自己的状态又根据这个状态继续执行。
SEQ阶段的实现
取指阶段
取指阶段包括指令内存硬件单元。以PC作为第一个字节的地址,这个单元读取10个字节。
- 第一个字节为Split单元:
- 高四位用来得到
icode - 第四位用来得到
ifunc
- 高四位用来得到
- 第二到十个字节为Align单元:
- 第一个字节用来得到
rA和rB根据高低四位得到 - 后八个字节用来得到8字节常数
valC
- 第一个字节用来得到
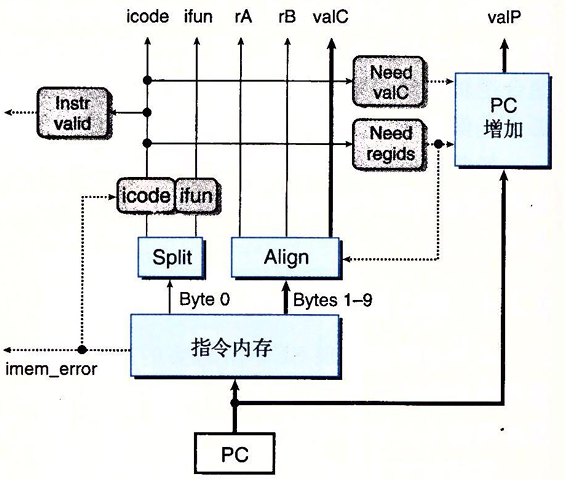
根据icode的值我们可以计算三个一位的信号:
- instr_valid:用来判断icode的是否是一个合法的指令
- need_registers:这个指令是否包括一个寄存器指示符字节
- need_valC:这个指令是否包括一个常数字
1 | # need_registers 实现 |
我们根据信号来获取rA rB valC,如果need_registers==1,第二个字节分开装入rA和rB。对于valC,如果need_registers==0&&need_valC==1,第二到九个字节装入常数字valC;如果need_registers==1&&need_valC==1,则将第三到十个字节装入常数字valC
PC增加器应将单元则根据当前的PC以及两个信号need_valC和need_registers的值得到信号valP。对于PC值p,need_registers值r,以及need_valC值i,增加器产生的值为PC = p + 1 + r + 8*i
译码和写回阶段
之所以将译码和写回阶段放在一起,是因为它们都要对寄存器文件进行访问。
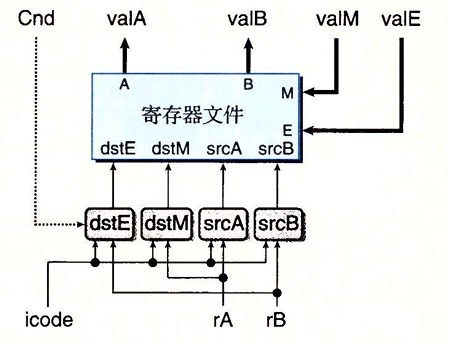
寄存器文件中有四个端口,其支持同时进行两个读(对端口A和B)和两个写(在端口E和M)。每个端口都有一个地址连接线(rArB)和一个数据连接线(icode)。地址连接线是寄存器ID,数据连接线则既可以做输出字也可以做读取字。两个读端口的地址输入为srcA和srcB,两个写端口的地址输入为dstE和dstM。如果某个地址端口上的值为0xF(RNONE)则代表不需要访问寄存器。
现在我们可以写出四个端口的输出情况:
1 | # srcA |
这里我们要额外注意一个问题当我们执行popq %rsp的时候同时有向%rsp写入valE和valM,因此我们要对dstE和dstM端口设置一个优先级,以确保最后%rsp的值是弹出的值,而不是更新后的%rsp值。因此我们将M端口的优先级设置的高于E端口。
执行阶段
执行阶段的硬件主要使用ALU,这个单元根据alufun信号的设置,对输入aluA aluB进行ADD SUB AND OR运算。这些数据和控制信号是由三个控制块产生的,valE就是ALU的输出。
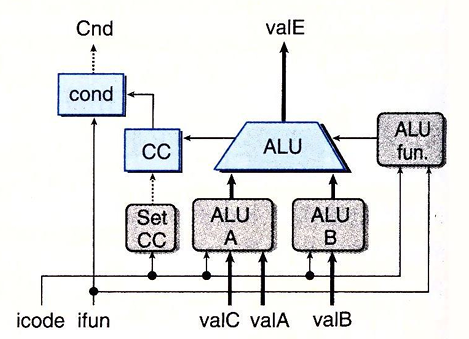
这里我们要明确,aluB是被计算的数,而aluB是用于计算的数。我们根据icode来选择性的设置aluA和aluB的值以完成计算
1 | # aluA |
同时我们要设置ALUfun,大多数时候ALU是做加法工作的,在执行OPQ指令时,对应ifun:
1 | # alufun |
执行阶段还要设置条件码寄存器。每次运行时要设置(零,符号,溢出),不过我们只希望在执行OPQ指令时才设置CC:
1 | if icode == OPQ: |
标号为Cond的硬件单元则会根据ifun和CC来设置信号Cnd,来确定是否要进行条件分支,或条件数据传送。它产生信号Cnd,用于设置条件传送的dstE,同时沿用在条件分支的下一个逻辑。对此我们可以设置指令CMOVXX的传送条件,即优化dstE的设置:
1 | # dstE |
访存阶段
该阶段的任务就是读写程序数据。两个控制块产生内存地址和内存输入数据的值。两外两个块产生表明读写操作的控制信号。当执行读操作时,数据内存产生值valM
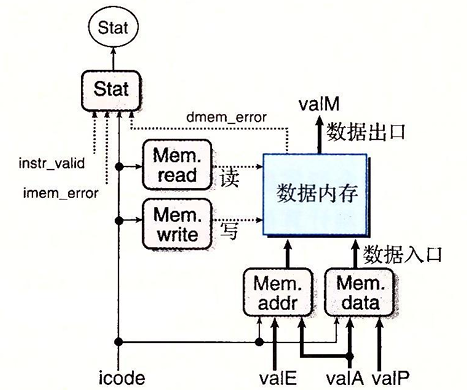
我们根据指令的访存阶段的分析,可以简单的得到Mem_addr和Mem_data的设置:
1
2
3
4
5
6
7
8
9
10# mem_addr
if icode in [RMMOVQ,PUSHQ,CALL,MRMOVQ]:
mem_addr = valE
else if icode in [POPQ,RET]:
mem_addr = valA
# mem_data
if icode in [RMMOVQ,PUSHQ]:
mem_data = valA
else if icode == CALL:
mem_data = valP
然后根据指令类型,判断数据内存读写的使用:
1 | # mem_read |
然后时是设置状态码,分别为SADR SINS SHLT SAOK
1 | # Stat |
更新PC阶段
SEQ的最后一个阶段会产生PC的新值,我们需要根据指令的类型和是否要选择分支来设置PC,PC可能是valC,valM,valP。
1 | # new_pc |
到此为止,我们的SEQ的各个阶段的硬件模拟就完成了。之后我们会进一步优化SEQ的实现。