这是第二遍学KMP算法,第一遍学习的过程中,对他的原理理解的是云里雾里。现在回过头来,深度学习一下KMP算法
首先我们要清楚什么是KMP算法?
KMP
KMP算法的优点相较于暴力匹配算法(BF)更有效率。这是因为KMP算法会利用每次匹配得到的已有的信息,来进行回溯。从而开始一次新的匹配。而暴力算法由于重复的匹配,其复杂度为
O(m*n);KMP算法的主串指针始终向前,所以复杂度为
O(m+n)
next数组
我看很多教程一开始都是先讲KMP算法的实现,只是提了一嘴next数组的大致内容,我觉得挺难懂的。所以这里先从next数组开始讲起:
要讲next数组,我们首先要从字符串的最大公共前后缀讲起,下面的图片很好的体现了这个概念。每次增大子串的长度,然后求得其对应的最大公共前后缀长度。
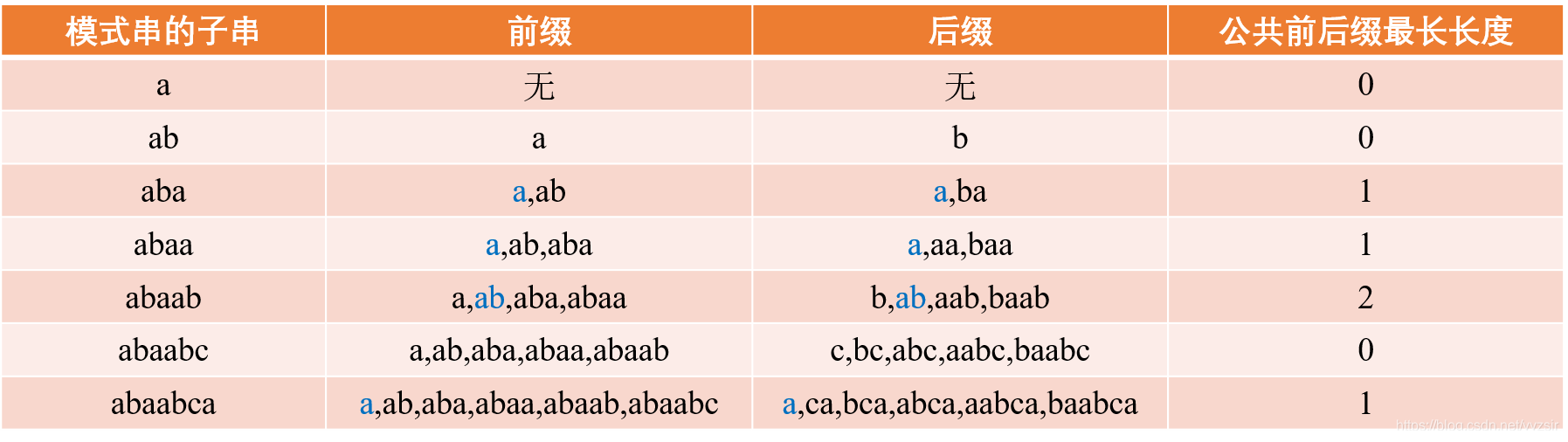
在求的子串的最大公共前后缀组后,我们便可以着手开始建立我们的next数组。
(1)首先我们需要明确next数组在这里的作用是什么?
当模式串的某个字符与主串的某个字符失配时,我们需要根据失配的位置
j,还有我们的
next数组,来确定下一次模式串开始匹配的位置。下一步用
next[j]处的字符继续与主串
i处的字符进行匹配。相当于将模式串向右移动了
j-next[j]的长度
(2)接下来的难点在于如何构建next数组
首先我们让 next[0] = -1作为一个标记,且我们容易得到
next[1] = 0,那么在此基础之上,我们需要结合现有的信息来递推下一个
next[j+1]的值。现在问题转换成了,如何利用已有信息,求下一个
next[j+1]的值?
对此我们需要分成两种情况进行判断:
- 当
p_k = p_j时,next[j+1] = next[j] + 1 = k+1,代表该字符前有最大长度为k+1的最大公共前后缀
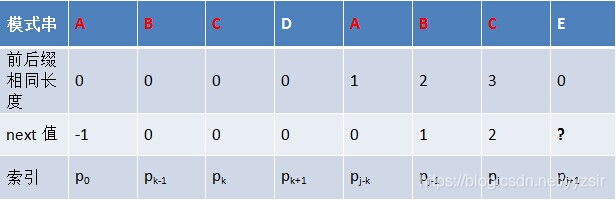
- 当
p_k != p_j时,我们就需要寻找更短的最大公共前后缀,此时关键来了,怎么找寻更短的最大公共前缀?
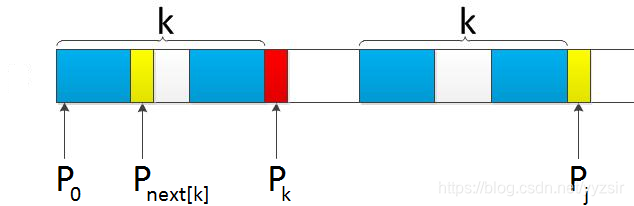
因为 P_k!=P_j,所以我们需要再次尝试
P_next[k]和
P_j的比较,如此一直递归下去。直到得到
P_next[next[...]]和 P_j相 等,从而令 next[j+1]
= next[index[P_next[…]]] + 1 = k+1;或者始终不能成功配对,则令
next[j+1] = 0
现在我们可以写出next数组的递推算法:
1 | void GetNext(char T[]){ |
这个程序还有一个递归版本:
1 | int GetNext(int j,char T[]){ |
KMP算法
我们在得到next数组之后,便可以根据next数组的特性和简单的判断,来实现我们的KMP算法,以下是我们的算法流程:
- 如果j = -1,则i++,j++,继续匹配下一个字符
- 如果S[i] = T[j],则i++,j++,继续匹配下一个字符
- 如果j != -1,且S[i] != P[j],则i不变,j = next[j]。这意味着失配,接下来模式串需要对主串相对右移j-next[j]的距离
现在我们可以写出完整的KMP算法:
1 | int KMP(int start,char S[],char T[]){ |
当然,在KMP的基础之上,还有很多优化之后的算法,在此就不过多赘述
Python版本
这个是python版本的KMP算法,基本上一样,只不过边界条件的判断改为使用长度判断。
1 | class Solution(object): |