书接上回 这一篇主要讲一下,当一个C语言函数在执行时,操作系统是如何调度内存将数据存放并完成相关函数操作的
C语言内存分布
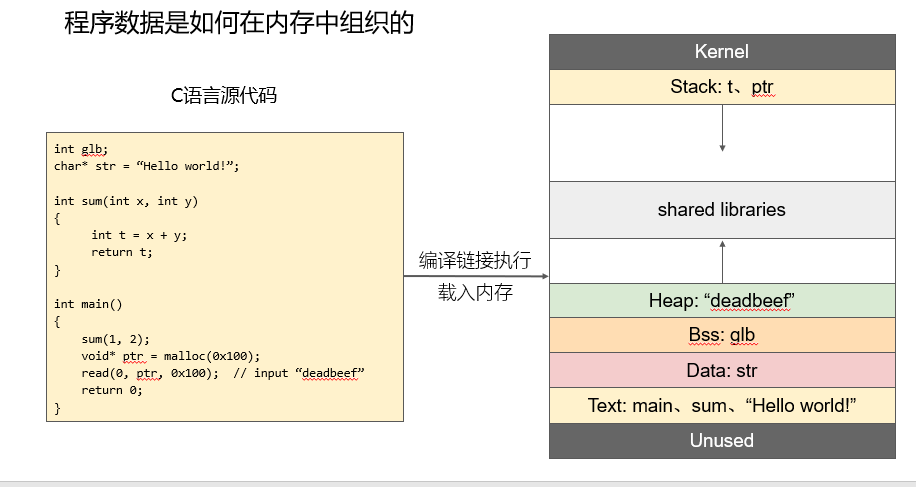
当一个C语言程序被编译成可执行文件执行时,它在内存中的存储如右图所示。这是一个内存空间,地址由底部逐渐升高:
- 其中顶层的Kernel是操作代码的核心源码,它是操作系统完成功能的关键
- 栈用于静态分配中的存放局部变量,例如程序中的局部变量t和ptr都被存储在栈中
- BSS存储未初始化的全局变量和静态变量
- Heap(堆)用于负责存储动态分配的内存空间比如malloc和free操作的内存空间
- data用于存储已经进行了初始化的全局变量
- 在heap和stack中间的内存空间,是一片共享的内存空间,heao从低地址向高地址分配空间,stack从高地址向低地址分配
栈中的内存分配与工作原理
现在分析一下函数调用时,栈的内存空间中是如何分配的
要了解栈,首先需要理解栈中常用的几个寄存器:
- 在32位中,我们用esp,ebp,eip三个寄存器
- 在64位中,我们用rsp,rbp,rip三个寄存器
接着我们需要了解一下栈帧的概念,一个栈帧就是保存一个函数的状态,简单地说,就是一个函数所需要的栈空间。
sp永远指向栈帧的栈顶, bp永远指向栈帧的栈底,
ip则指向当前栈栈帧执行的命令。
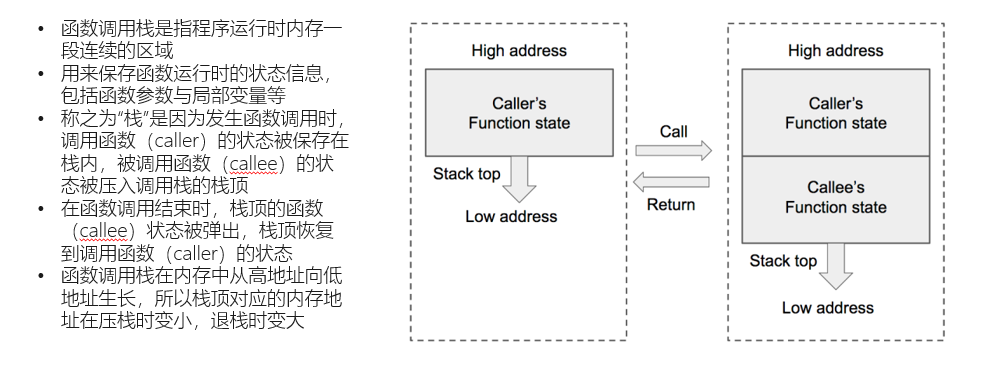
我们现在可以分析一下函数调用的过程,栈底的第一个栈帧存储着我们的主函数的父函数,所以说main实际上并不是第一个栈帧,在main之前还有一些编译过程中产生的库文件,只不过不产生栈帧。
当我们在main中调用其他函数时,我们便在栈中开辟一块新的栈帧,并在其中存储上一个栈的栈底,当函数调用结束时,我们就将现在的栈帧弹出,恢复到原来的main函数继续执行完main函数。
那么,至此我们需要进一步的对栈帧的具体结构进行讲解。首先是栈帧的创建:
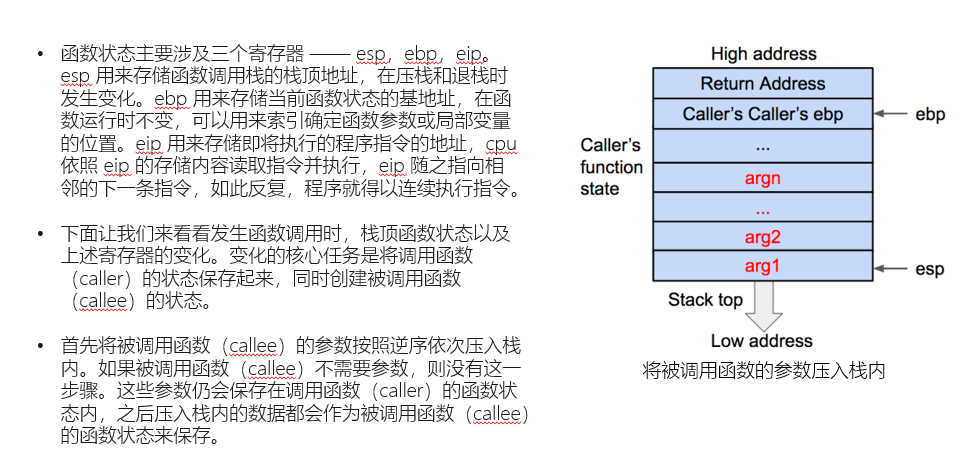
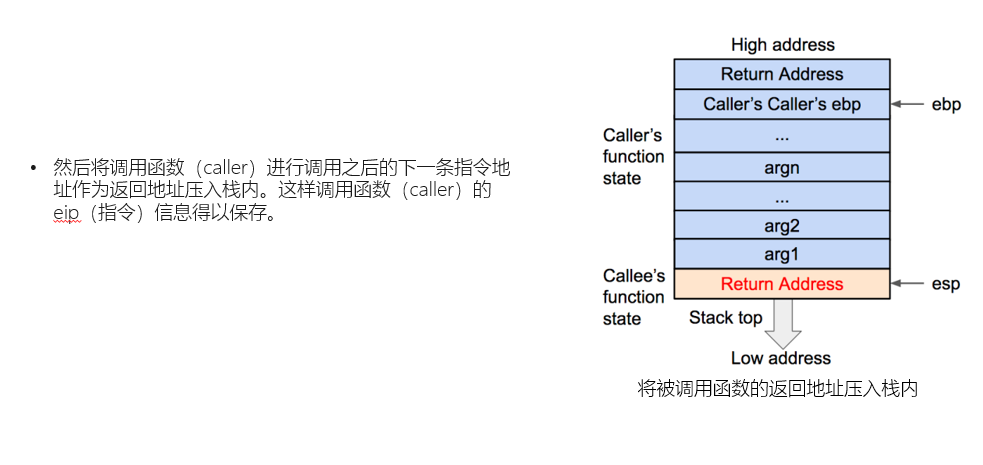
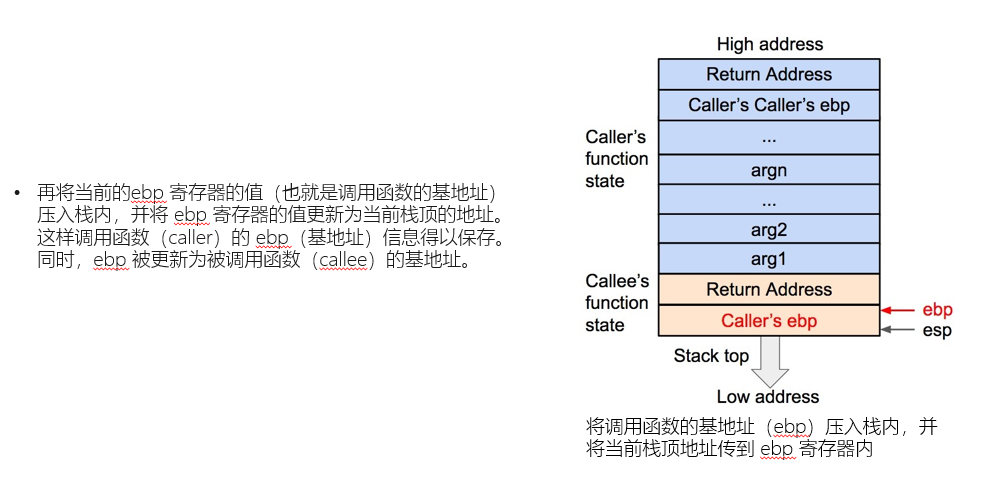
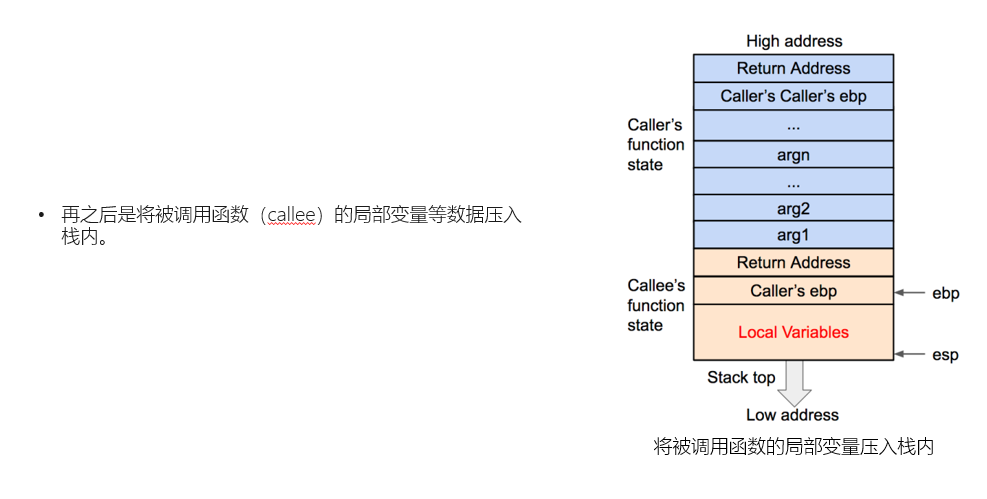
以上是一个栈帧建立的过程,我们注意到新栈帧底部的返回地址。这是栈溢出使用的关键,这个返回地址的实际作用是在当前栈帧结束后,弹出至ip,实现函数返回。而在栈溢出的攻击中,我们可以通过覆盖/修改返回地址的内容,使其指向我们想要的后门函数。这就是栈溢出攻击的原理
我们接下来进一步看看栈帧的返回过程:
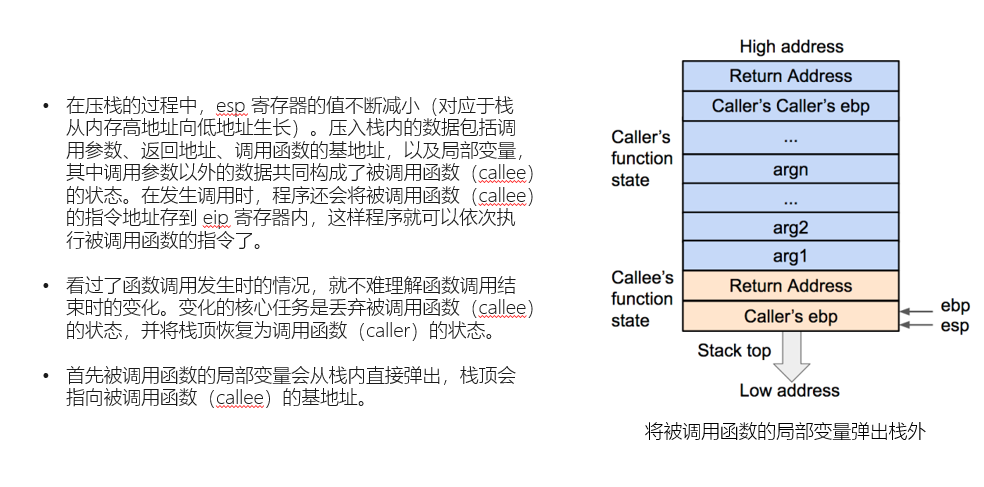
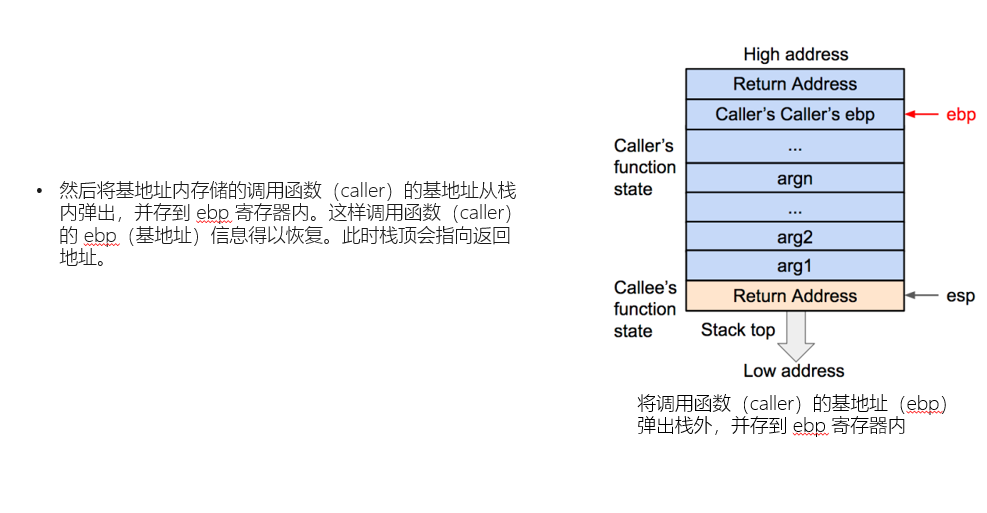
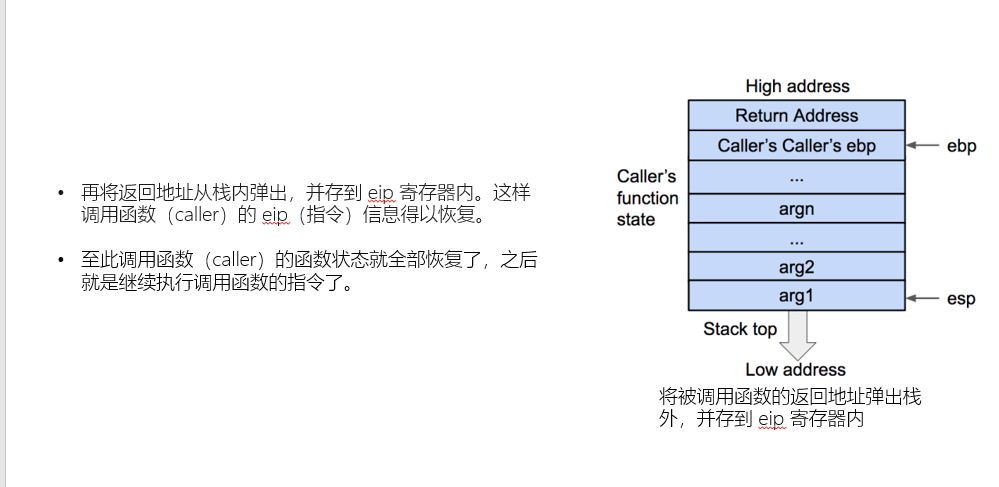
这里我们需要注意返回地址实际上是调用函数指令的下一条,并不是我们理解的返回函数入口。
在这些PPT中我们可以感受到一个函数返回的过程:
- 首先是撤销我们的栈帧中的局部变量,我们直接弹出即可
- 然后我们将原函数的栈底弹出,恢复原来栈底
- 再将返回地址弹出,让函数继续执行
这样的一个过程便是函数调用与返回,通过图片的形式展现出来。
栈溢出攻击
在学习了函数返回的原理之后,我们明确,只要想办法修改返回地址即可实现攻击
那么我们在哪一步中有机会实现这个操作呢?
我们可以通过将局部变量溢出来实现攻击,但是并非所有的情况下都能实现攻击。不过当程序中使用了
gets的有安全隐患的函数时,因其并没有设置边界,理论上是可以栈溢出至返回地址,并将其覆盖的。
我们可以写出常见的攻击脚本:
1 | from pwn import * |