这里我们接下来使用TurboC2来尝试编写可执行程序,它是一个可以在DOS十六位上运行的C语言编辑器,我们使用C语言来进一步的对8086进行学习
有关Turbo2C的安装到网上找教程即可
使用寄存器
在汇编中使用寄存器,需要指定寄存器名,在C语言中也是如此
我们可以tc2.0支持以下寄存器名
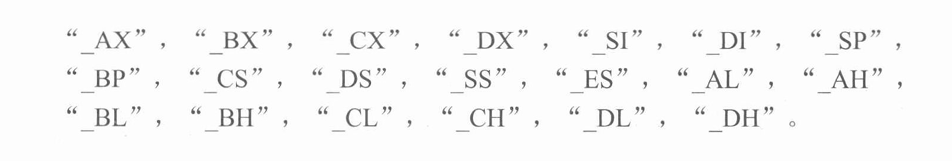
根据寄存器名称可以理解对应的寄存器关系
我们进行以下思考
- 用TurboC编译出来的可执行程序和用masm编译出来的程序有什么区别?
首先我们用turboC写出以下程序然后进行编译
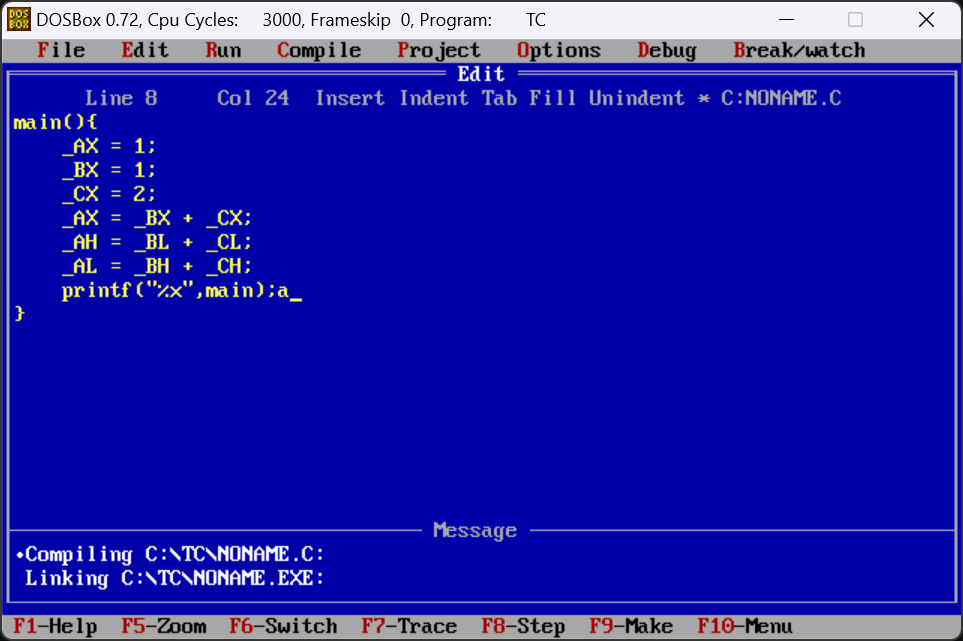
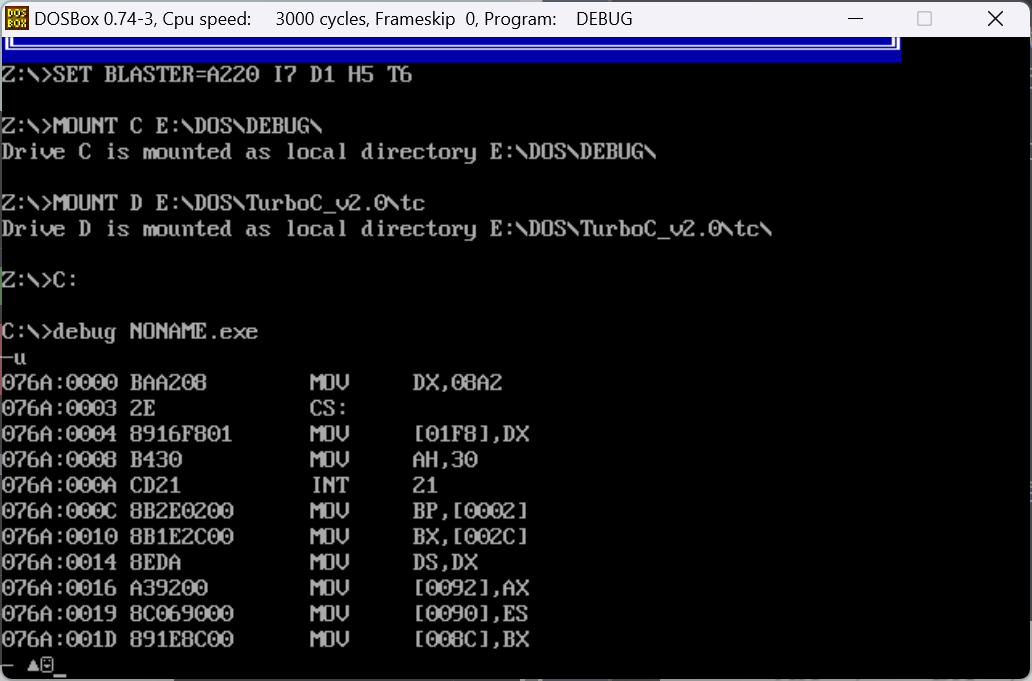
我们注意到当我们查看debug时看到的汇编代码和我们写的C语言程序并不一样
此时我们思考下一个问题:
- main函数的代码在什么段中,我们怎么找到它?
在这里我将答案写在了我的源程序中,我们可以看到
printf("%x",main)
这一条指令的作用是答应出main函数在代码段中的偏移地址:
0x01FA
这里还需要注意,为什么可以用main来找到其在代码段中的偏移地址。这是因为在这里,main是一个标号,并不是一个变量。我们可以通过printf("%x",&main)来验证,如果main是变量,那么此时打印出来的是main变量的存储地址,然而实际上main是一个直接指向代码段地址的标号
所以我们可以定位到我们的程序,并看到我们写的程序逻辑:
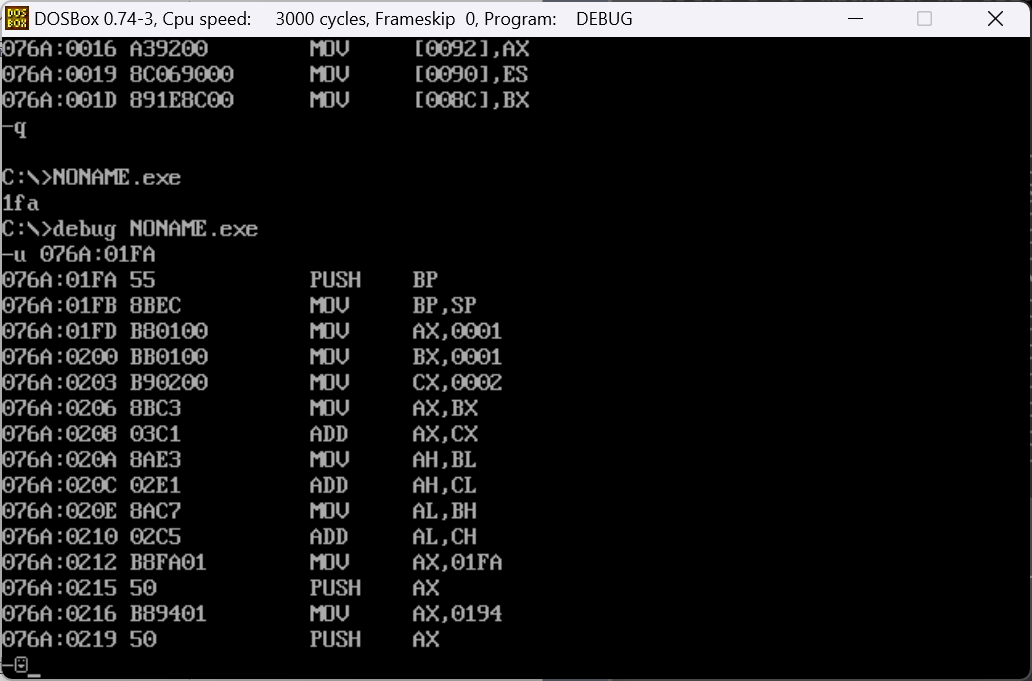
- 那么程序DEBUG时我们,一开时看到的内容是什么?
我们可以判断添加这一部分内容的肯定时编译连接程序,所以其作用,可能与程序执行前后的饿现场保护,系统调度有关系。那么,这多出来的部分应该是固定的,与我们编写的程序无关。所以在 上面拿到的偏移地址,对于所有的程序都是一样的。
- 我们在程序中看到main函数后有ret指令,因此我们可以设想:C语言将函数实现为汇编中的子程序。但是如何验证?
我们编写一个有函数调用过程的C程序即可
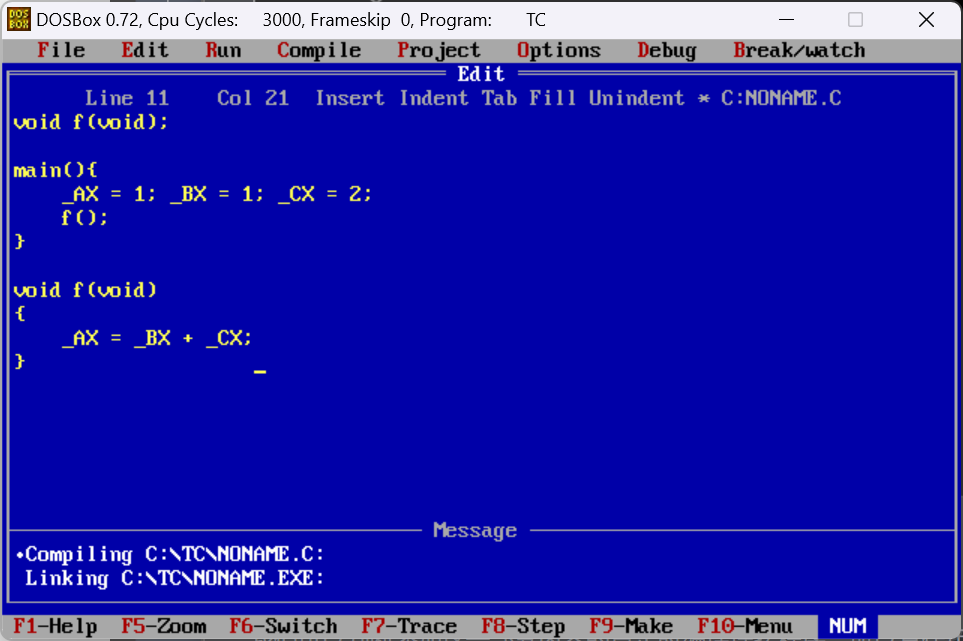
我们通过调试打开可以看到
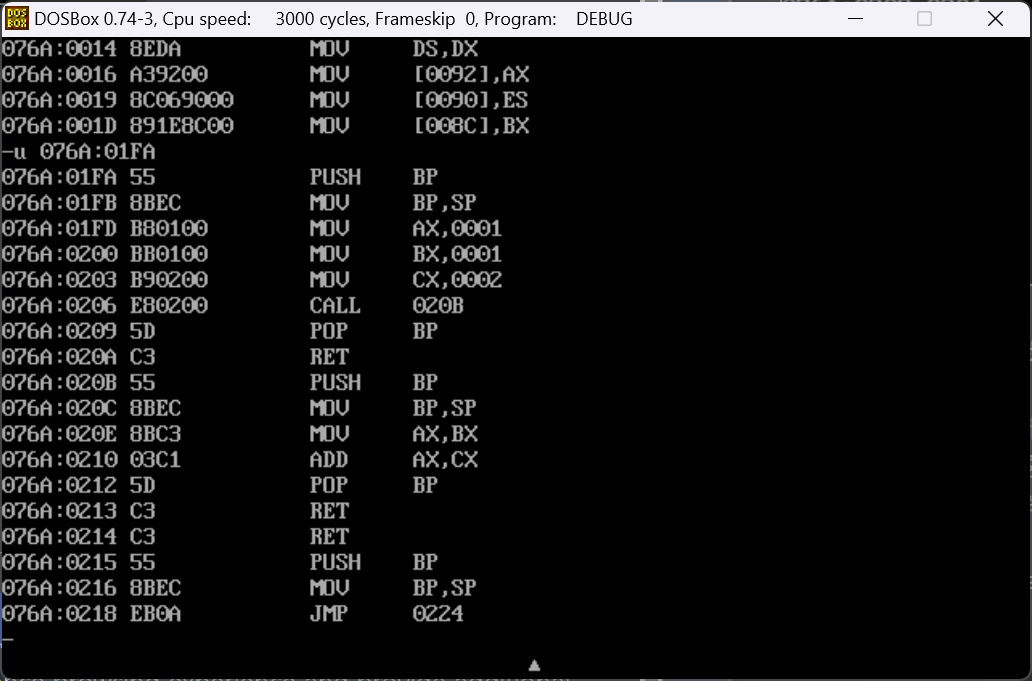
在这里看可以看到函数的调用过程,实际上就是子程序的调用
使用内存空间
首先要明确内存空间的使用,对于寄存器而言,我们需要给出寄存器的名称,寄存器的名称中也包含了他们的类型信息。而对于内存空间我们同样也需要给出内存地址(准确的说是内存空间首地址)和空间存储数据的类型。
现在我们对一些C语言的指令进行分析:
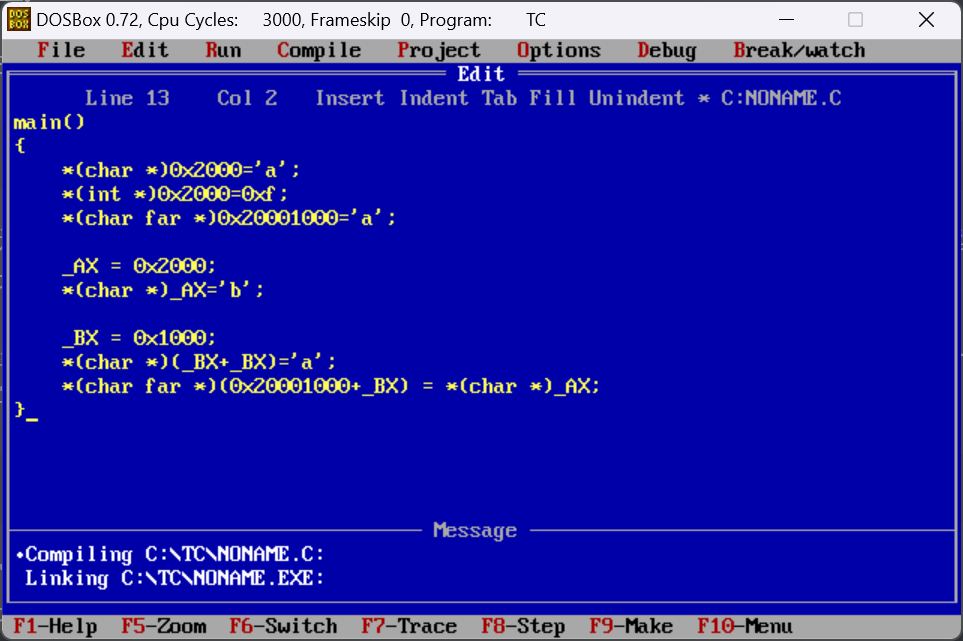
1 | *(char *)0x2000 = 'a'; |
这里我们的第一个*是访问内存空间地址的意思,而(char *)则是指明这是一个存储char型数据的内存空间地址
当然我们也可以直接使用给出段地址和偏移地址,比如我们要向一个地址为
2000:0存储一个字节的内存空间写入字符a
1 | *(char far *)0x20000000='a'; |
“far”指明内存空间的地址是段地址和偏移地址,而0x20000000中的0x2000给出了段地址,0000给出了偏移地址
当然这种对内存空间进行直接访问的方式是不安全的,我们可能无意间修改了别的程序的代码或者数据,从而引起错误
(1)首先编写一个程序,看看C语言的内存空间使用,在汇编中是以什么形式呈现?
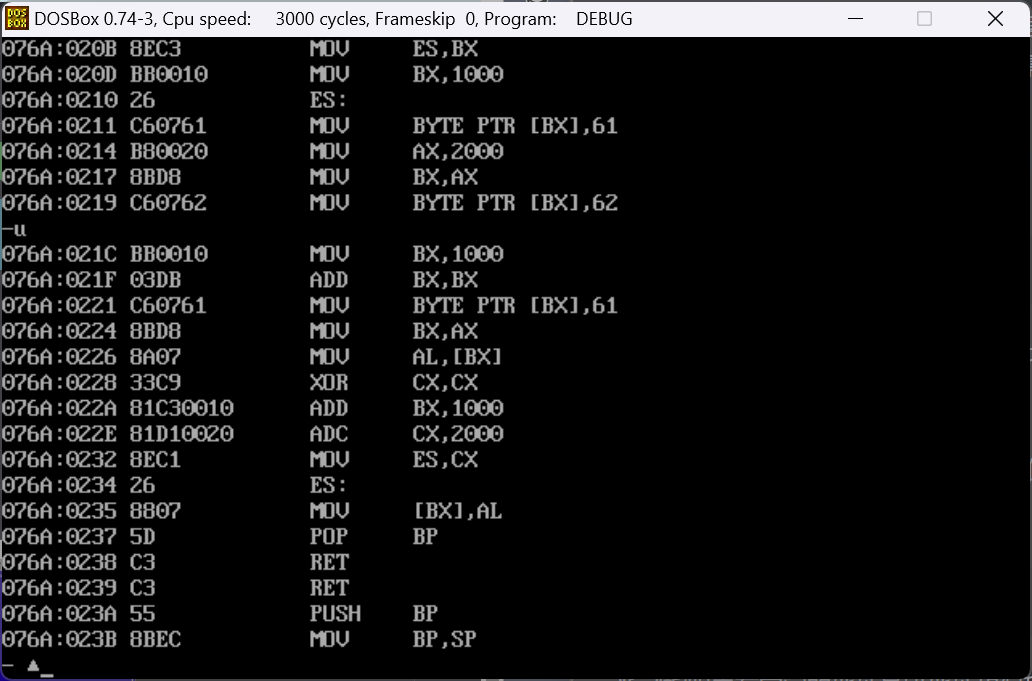
我们可以看到汇编中的完成方式(由此可以感受到汇编与C的相似性)
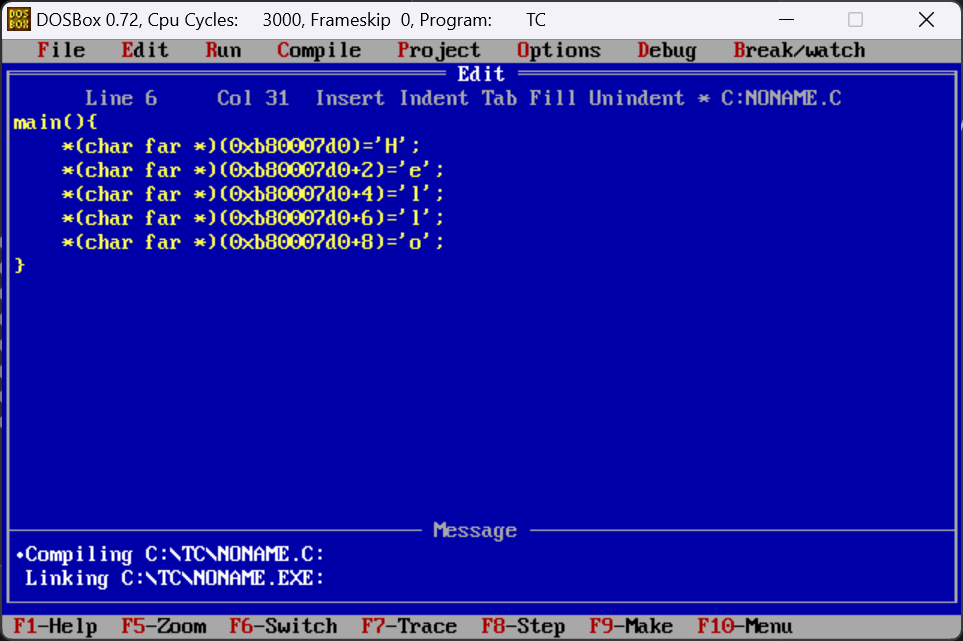
(2)现在我们尝试在C语言中写一个程序来实现打印字符”Hello”
简单粗暴的方法
(3)那么我们现在进一步的思考,C语言将全局的变量存放在哪里?将局部变量又存放在哪里?每个函数开头的push bp mov bp sp又有什么意义?分析以下代码思考一下
1 | int a1,a2,a3; |
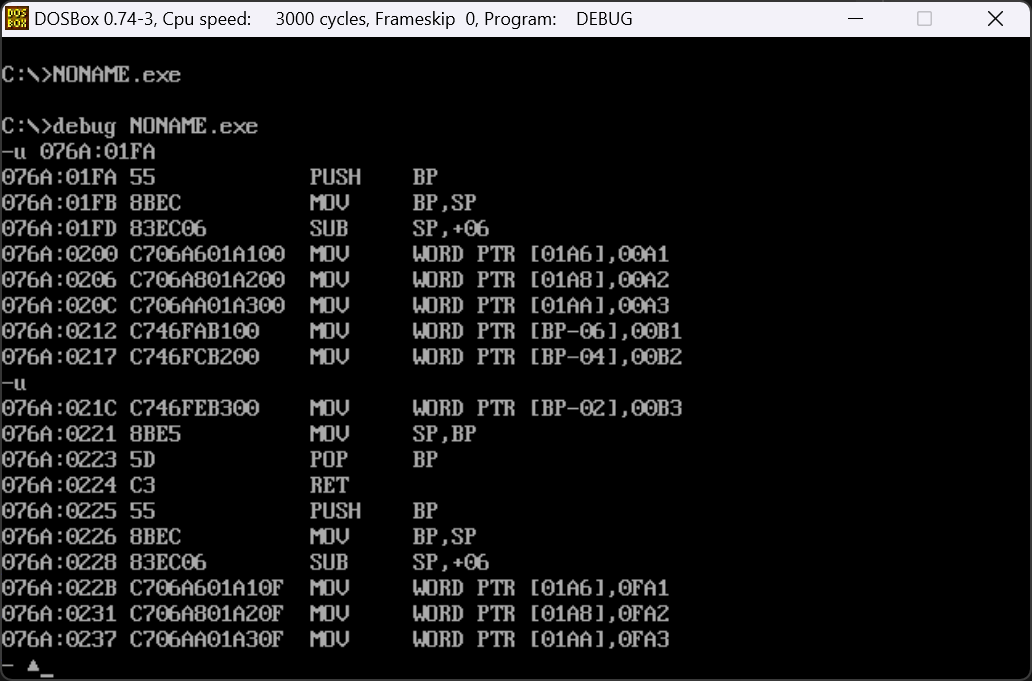
我们看到
SUB SP,+06将栈顶下移了6个字节用来存放局部变量,为什么是存放局部变量而不是全局变量呢,在存储的过程中,我们可以看到对于全局变量,是使用直接定址的方法进行存储在程序的数据段中,而对于局部变量则是以栈底的相对位置进行访问。由此可以看出,局部变量以栈的形式存储在函数的同一个栈中。
在这里我们便可以理解push bp mov bp sp的意义,通俗来讲。这是因为全局变量被存储于数据段中,而局部变量被存储于栈段中,和函数功能存放在一起,而这段指令则是用于创建一个新的函数栈帧。
我在下一篇博客中会详细讲解这个过程。
(4)此时我们进一步思考,函数的返回值被存放在哪里?分析下面的程序
1 | int f(void); |
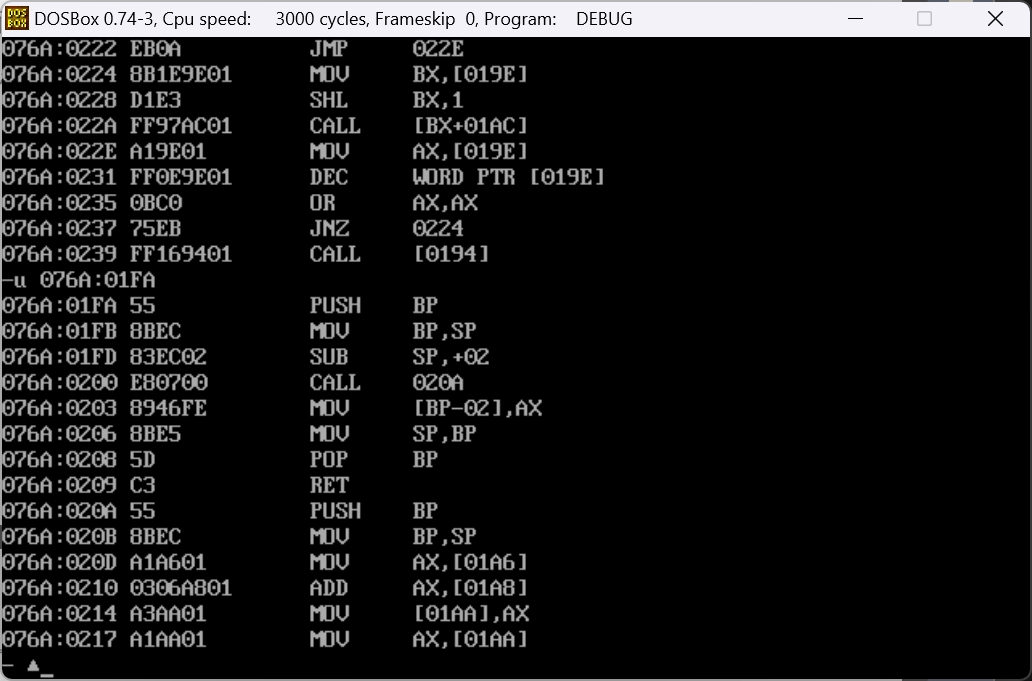
我们很容易理解前面的逻辑,其中
[01A6],[01A8],[01AA]都是全局变量的位置,但是此时我们注意到
MOV AX,[01AA]观察可以得到,在这里函数的返回值通过寄存器的方式返回。
(5)理解内存的创建与释放?分析以下函数
1 |
|
气死了,这个实验不知道为什么做的很不成功,先是没办法正常分配内存,然后再是拿不到正常的返回值,算了算了
不用main函数编程
现在我们讨论一个问题,如果一个C程序中它没有使用main函数编程,那它是否能被编译并正常运行呢?
现在我们准备两个程序
1 | f(){ |
1 | main(){ |
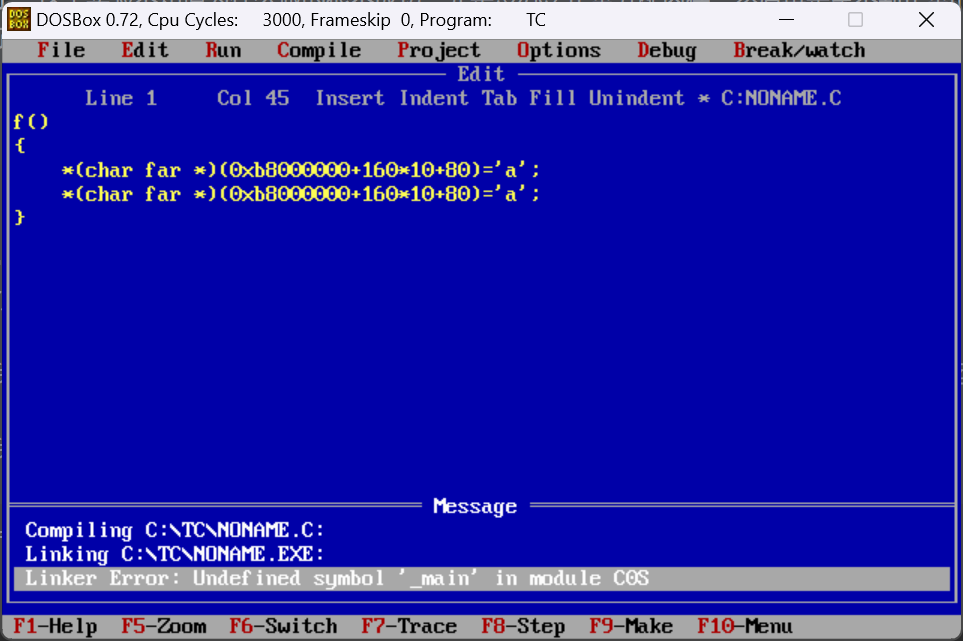
我们在对F.exe进行编译后出现了如下报错,且编译失败,故我们用link对F.obj进行编译
接下来我们分别运行M.exe和F.exe,运行结果如下:
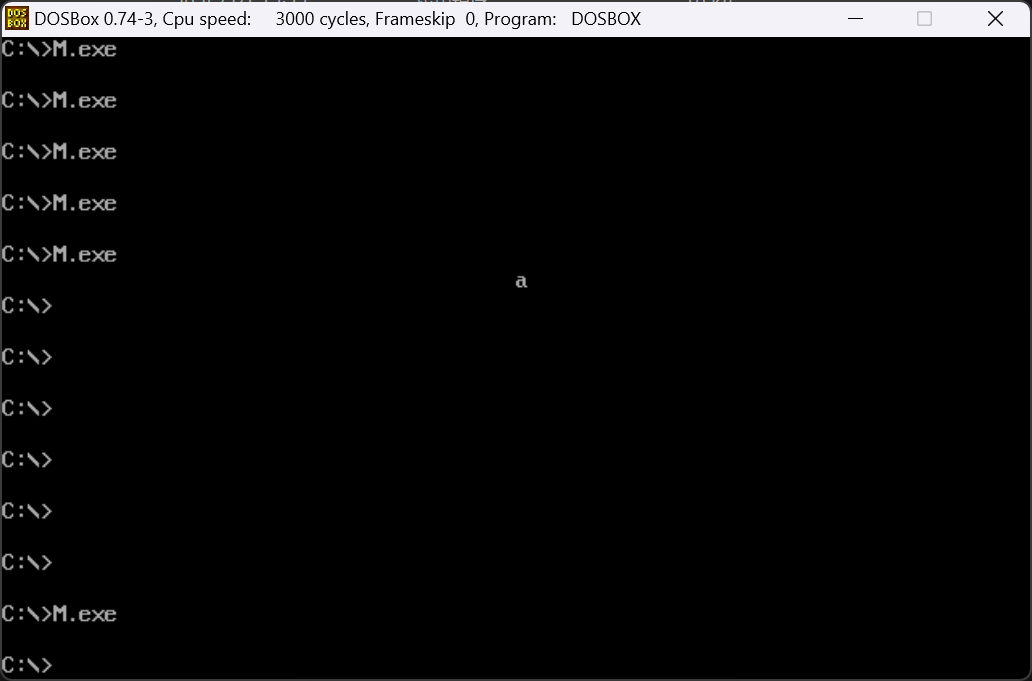
M运行后正常显示并正常返回,但是F出现了一些情况。虽然a的显示是正常的,但是F运行之后,程序卡死,无法返回正常的操作
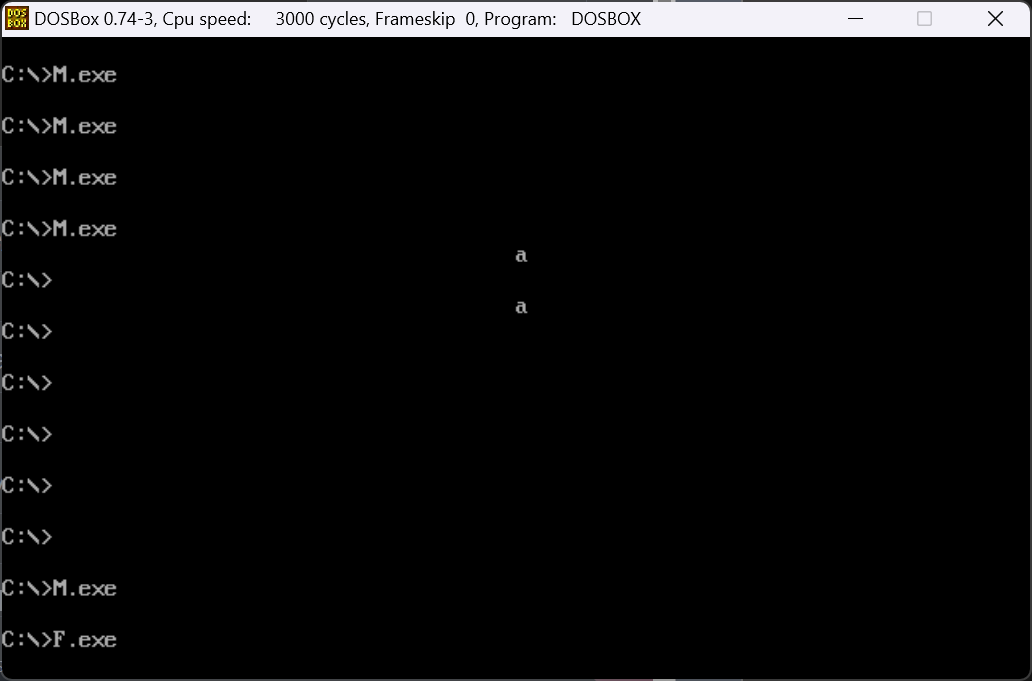
这是为什么呢,我们观察两个程序的大小

发现M程序的大小远大于F程序,说明M程序中包含了跟多的指令和信息,我们对其分别进行反汇编,发现相较于M程序,F程序只是一个孤零零的子程序只有入口却没有返回。而M程序则是一个完整的程序,且在01FA之前,有着完整的程序
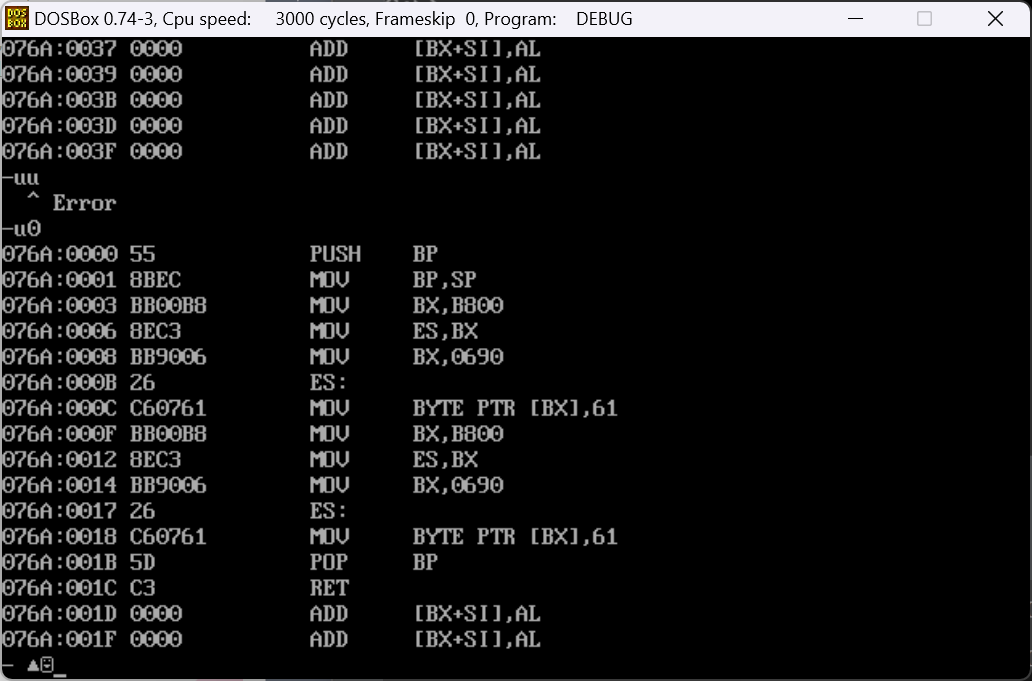
而且相较于F程序,M程序的子程序结尾多了
RET PUSH BP MOV BP,SP这一部分的作用是用于函数返回,恢复原栈帧用的
现在我们可以好好分析一下二者的区别:
- 首先main函数被作为了一个子程序,且在编译时被添加了很多代码
- f函数则是作为一个子程序被直接调用却没有返回
因此,问题出在main函数被编译连接的过程中,我们回想f函数编译失败的报错
Linker Error:Undefined symbol _main in module C0S我们可以猜测,在连接的过程中,连接器把main.obj与C0S.obj连接在了一起,得到我们的main.exe函数。此时我们可以进一步的推断,01FA地址以前的程序都是来自COS.obj中。接下来我们对此进行验证:
我们在lib文件夹下面找到C0S.obj文件并将其编译,然后对执行程序进行反编译
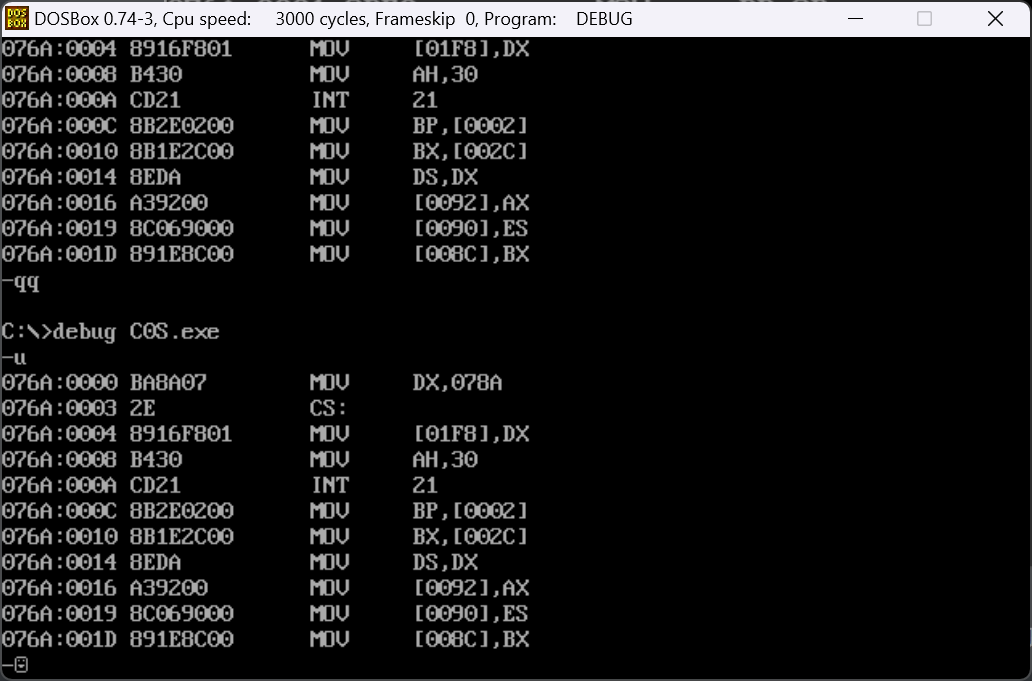
我们发现这部分代码和01FA以前的代码很像啊,几乎一样,所以我们可以认定main函数以前的代码都与C0S是有关系的
从上面我们可以看出,tc.exe把c0s.obj和用户.obj文件一同进行连接,生成.exe文件。按照这个方法生成.exe文件中的程序的运行过程如下:
- c0s.obj中的程序先运行,进行相关的初始化,比如,申请资源,设置DS,SS等寄存器
- c0s.obj中的程序调用main函数,从此用户程序开始运作
- 用户程序从main函数中返回到c0s.obj的程序中
- c0s.obj程序接着运行,进行相关资源的释放,环境恢复等问题;
- c0s.obj的程序调用DOS的int 21h例程的4ch号功能,程序返回
所以看来C语言程序必须从main函数开始,是C语言的规定,这个规定不是在编译时保证的,也不是连接的时候保证的,而是用下面的机制保证的:
- 首先,C开发系统提供了用户写的应用程序正确运行所必须的初始化和程序返回等相关程序,这些程序被存放在相关的.obj程序中
- 其次,需要将这些文件和用户.obj文件一起连接,才能生成可正确运行的.exe文件
- 基于这个机制,我们只需要改写c0s.obj,让它调用其他函数,编程时就可以不写main函数了
现在我们自己写一个简单的c0s.obj程序:
1 | assume cs:code |
我们尝试将它和f.obj连接在一起看看能不能生成可正确执行的可执行程序
OK ,经过不懈的努力我们也是成功连接出了一个可正确执行的可执行程序。
这里需要补充一下连接多个目标文件的用法
link file1.obj file2.obj...;
函数如何接受不定数量的参数
给定参数的函数参数传递
我们通过一个简单的程序来研究两个问题,main函数时如何给showchar传递参数的?showchar是如何接受参数的?
1 | void showchar(char a,int b); |
我们先编译成可执行程序后,反汇编其代码:
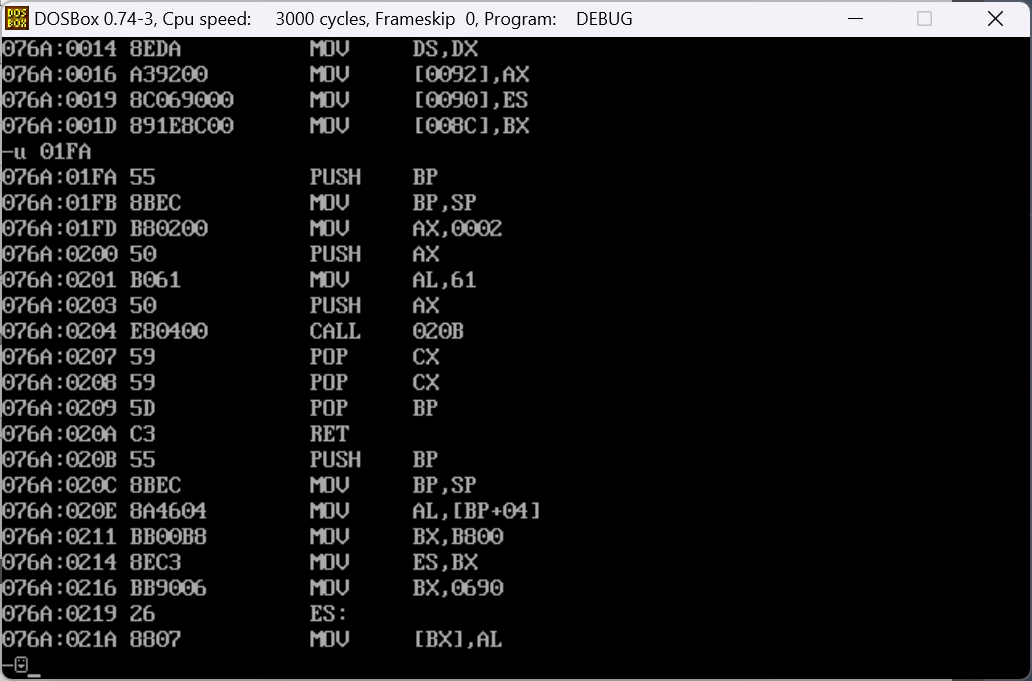
我们可以看到一个下面这样的栈结构:
1 | 内存地址 (低地址) |
我们可以看到在函数调用传入参数时,是以栈底为基础相对位移对传入的参数进行访问。也就是说,依次向AL中传入的数值便是我们的参数。
总结得到C语言中参数的传递是通过栈来实现的。在函数调用前,将参数放入AX中,进入调用函数后,先把参数中的值出栈到AX中。这样就完成了函数间参数值的传递工作。其次我们还需要注意:在参数入栈中首先入栈的是后面的参数,即入栈时为倒序入栈,这是因为栈先进后出的特性
不定参数个数的函数传参
我们编写一个不定参数个数的函数后进行分析
1 | void showchar(int,int,...); |
这里我用AI画了一个栈段图,可以更形象的理解这个调用的过程
1 | +-------------------+ |
因此就不过多赘述了,这便是函数传递参数的原理
写一个printf函数
知道了传递参数的原理,我们写一个简单的print函数来结束对于TurboC 的简单学习
功能:实现一个支持%c,%d的printf函数
1 | void print(char *str,...); |
至此对于8086的简单学习到这里结束了